Implement union, intersection, union_counts, and intersection_counts#22
Implement union, intersection, union_counts, and intersection_counts#22HarrisonMc555 wants to merge 3 commits into
Conversation
The `union` and `union_counts` methods return iterators that yield elements the maximum number of times they appear in either set. This is different from the previously implemented `Add` trait, which yields each element the combined number of times it appears in both sets. The `intersection` and `intersection_counts` methods return iterators that yield elements the minimum number of times they appear in either set. This is distinct from the previously implemented `Sub` trait, which yields each element the number of times it appears in the first set less the number of times it appears in the second. The different between the plain variants and the `_counts` variants is that the former yields only the elements (repeated the correct number of times) while the latter yields a tuple of an element and the count of that element.
|
I just realized that I didn't add any documentation to the new |
|
I feel like it might be confusing to have |
|
Honestly, I implemented I also think that you should be able to construct a collection from the result of an iterator over it. An iterator over key/count pairs cannot be used to construct a ...unless it could. We could add (I wrote one earlier to test it out) another implementation of The only issue with this is that now you have overlapping implementations of let set1: HashMultiSet<_> = [1, 2, 2, 3, 3, 3].iter().cloned().collect();
let set2: HashMultiSet<_> = [1, 1, 1, 3, 4].iter().cloned().collect();
let union: HashMultiSet<_> = set1.union(&set2).collect();You'll get this error: You have to be more specific, and write this: let set1: HashMultiSet<_> = [1, 2, 2, 3, 3, 3].iter().cloned().collect();
let set2: HashMultiSet<_> = [1, 1, 1, 3, 4].iter().cloned().collect();
let union: HashMultiSet<&u32> = set1.union(&set2).collect();This also demonstrates that it can be obnoxious to use, since a call to You'd have to write something like this: let union: HashMultiSet<u32> = set1
.union_counts(&set2)
.map(|(&key, count)| (key, count))
.collect();Which is a little bit annoying. As a consolation, So I'm totally up for feedback or ideas! P.S. I totally forgot that I left the second implementation for |
|
Looking at the python multiset and the C++ |
|
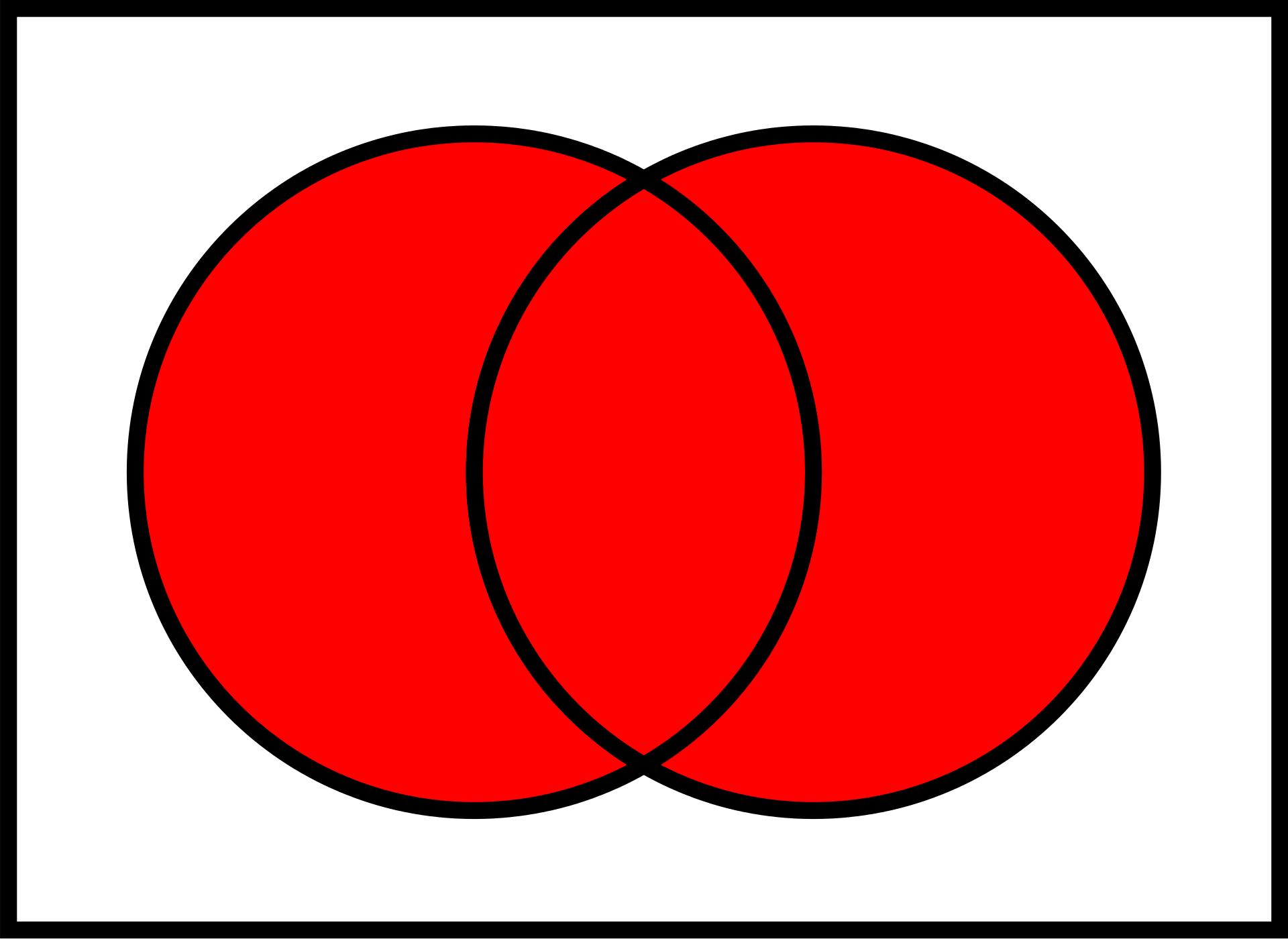
Looks like there are two different concerns here. Let's address each of them. 1. Definition of "union"I think we have different ideas of what a "union" should mean in the context of a multiset. Let's explore it a little bit. SetSince sets do not contain duplicates, a union of two sets contains every value that appears in either set, without duplicates. Map (Dictionary, etc.)Since maps contain keys and values, it's unclear which value would "win" if a key is present in both maps. The Rust Multiset (Bags, etc.)A multiset is conceptually a set that can contain duplicates. In my mind, a union is thought of as the "overlap" between the two sets.
In my mind, a union between two multisets would contain each value the maximum number of times it appears in either set. If the union contained the sum of the two sets, it would be more than the overlap. The implementation you suggested, where each value appears the sum of the times it appears in both sets is a useful concept. It is the current implementation of the I would prefer to implement union as I have proposed and keep the implementation of the 2. Should we keep the "
|
|
Yeah sorry, you seem to be right about union! That's also what the python multiset union does. Not sure why I thought otherwise. Yes Looking at the Collection Conventions RFC we could do it in-place and call it No I don't know the best solution. Just thinking out loud. |
The
unionandunion_countsmethods return iterators that yield elements the maximum number of times they appear in either set. This is different from the previously implementedAddtrait, which yields each element the combined number of times it appears in both sets.The
intersectionandintersection_countsmethods return iterators that yield elements the minimum number of times they appear in either set. This is distinct from the previously implementedSubtrait, which yields each element the number of times it appears in the first set less the number of times it appears in the second.The difference between the plain variants and the
_countsvariants is that the former yields only the elements (repeated the correct number of times) while the latter yields a tuple of an element and the count of that element.This closes #17.
I'm totally willing to take feedback on implementation, naming, or even whether you want to include all of these changes or not.
Let me know what you think!