ConcurrentHashMap
The ConcurrentHashMap is very similar to the HashMap class, except that ConcurrentHashMap offers internally maintained concurrency. It means you do not need to have synchronized blocks when accessing ConcurrentHashMap in multithreaded application. ConcurrentHashMap class is introduced in JDK 1.5, which implements ConcurrentMap as well as Serializable interface also.
- The underlined data structure for ConcurrentHashMap is Hashtable.
- ConcurrentHashMap class is thread-safe i.e. multiple thread can operate on a single object without any complications.
- At a time any number of threads are applicable for read operation without locking the ConcurrentHashMap object which is not there in HashMap.
- In ConcurrentHashMap, the Object is divided into number of segments according to the concurrency level.
- Default concurrency-level of ConcurrentHashMap is 16.
- In ConcurrentHashMap, at a time any number of threads can perform retrieval operation but for updation in object, thread must lock the particular segment in which thread want to operate.This type of locking mechanism is known as Segment locking or bucket locking.Hence at a time 16 updation operations can be performed by threads.
- null insertion is not possible in ConcurrentHashMap as key or value.
- Concurrency-Level: Defines the number which is an estimated number of concurrently updating threads. The implementation performs internal sizing to try to accommodate this many threads.default is 116.It means 16 Shards whenever we create an instance of ConcurrentHashMap using default constructor, before even adding first key-value pair. It also means the creation of instances for various inner classes like ConcurrentHashMap$Segment, ConcurrentHashMap$HashEntry[] and ReentrantLock$NonfairSync.
- Load-Factor: It's a threshold, used to control resizing.
- **Initial Capacity: **The implementation performs internal sizing to accommodate these many elements.
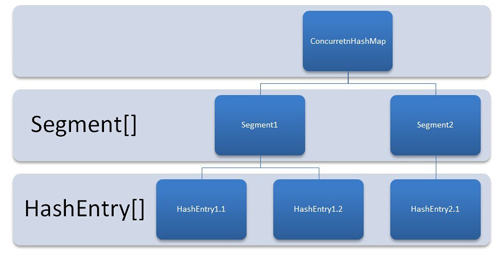
A ConcurrentHashMap is divided into number of segments, and its being calculated by next power of two based on cocurrency level. for example
- If level is 6 then segments are 8.
- If 16 then segments are 32
- If 65 the segments are 128
Calculation formula is
**static final int MAX_SEGMENTS = 1 << concurrency Level ;**
Internal Structure of Concurrent Hash map
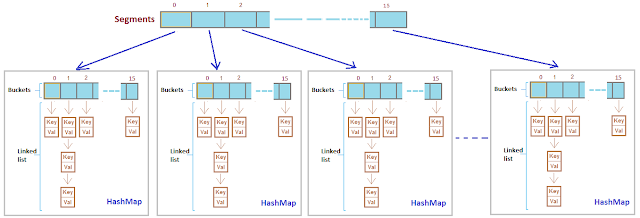
A ConcurrentHashMap has internal final class called Segment so we can say that ConcurrentHashMap is internally divided in segments of size 32, so at max 32 threads can work at a time. It means each thread can work on a each segment during high concurrency and atmost 32 threads can operate at max which simply maintains 32 locks to guard each bucket of the ConcurrentHashMap.
** Inner Segment class plays a significant role **/
protected static final class Segment {
protected int count;
protected synchronized int getCount() {
return this.count;
}
protected synchronized void synch() {}
}
/** Segment Array declaration **/
public final Segment[] segments = new Segment[32];
As we all know that Map is a kind of data structure which stores data in key-value pair which is array of inner class Entry, see as below:
static class Entry implements Map.Entry {
protected final Object key;
protected volatile Object value;
protected final int hash;
protected final Entry next;
Entry(int hash, Object key, Object value, Entry next) {
this.value = value;
this.hash = hash;
this.key = key;
this.next = next;
}
// Code goes here like getter/setter
}
And ConcurrentHashMap class has an array defined as below of type Entry class:
protected transient Entry[] table;
his Entry array is getting initialized when we are creating an instance of ConcurrentHashMap, even using a default constructor called internally as below:
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
//Some code
int cap = getCapacity();
this.table = newTable(cap); // here this.table is Entry[] table
}
protected Entry[] newTable(int capacity) {
this.threshold = ((int)(capacity * this.loadFactor / 32.0F) + 1);
return new Entry[capacity];
}
**put(Object key, Object value) **
1. Hash Calculation
int hashVal = hash(key);
static int hash(Object x) {
int h = x.hashCode();
return (h << 7) - h + (h >>> 9) + (h >>> 17);
}
2. Segment Decision
Segment seg = segments[(hash & 0x1F)];
**3. Segment Synchronization**
synchronized (seg) {
// code to add
int index = hash & table.length - 1; // hash we have calculated for key and table is Entry[] table
Entry first = table[index];
for (Entry e = first; e != null; e = e.next) {
if ((e.hash == hash) && (eq(key, e.key))) { // if key already exist means updating the value
Object oldValue = e.value;
e.value = value;
return oldValue;
}
}
Entry newEntry = new Entry(hash, key, value, first); // new entry, i.e. this key not exist in map
table[index] = newEntry; // Putting the Entry object at calculated Index
}
implementation below
public Object get(Object key){
//some code here
int index = hash & table.length - 1; //hash we have calculated for key and calculating index with help of hash
Entry first = table[index]; //table is Entry[] table
for (Entry e = first; e != null; e = e.next) {
if ((e.hash == hash) && (eq(key, e.key))) {
Object value = e.value;
if (value == null) {
break;
}
return value;
}
}
//some code here
}
for (int i = 0; i < this.segments.length; i++) {
c += this.segments[i].getCount(); //here c is an integer initialized with zero
}
Now question is how remove works with ConcurrentHashMap, so let us understand it. Remove basically takes one argument 'Key' as an argument or takes two argument 'Key' and 'Value' as below:
Object remove(Object key);
boolean remove(Object key, Object value);
Now let us understand how this works internally. The method remove (Object key) internally calls remove (Object key, Object value) where it passed 'null' as a value. Since we are going to remove an element from a Segment, we need a lock on the that Segment.
Object remove(Object key, Object value) {
Segment seg = segments[(hash & 0x1F)]; //hash we have calculated for key
synchronized (seg) {
Entry[] tab = this.table; //table is Entry[] table
int index = hash & tab.length - 1; //calculating index with help of hash
Entry first = tab[index]; //Getting the Entry Object
Entry e = first;
while(true) {
if ((e.hash == hash) && (eq(key, e.key))) {
break;
}
e = e.next;
}
Object oldValue = e.value;
Entry head = e.next;
for (Entry p = first; p != e; p = p.next) {
head = new Entry(p.hash, p.key, p.value, head);
}
table[index] = head;
seg.count -= 1;
}
return oldValue;
}
**Why we need ConcurrentHashMap when we already had Hashtable ** Hashtable provides concurrent access to the Map.Entries objects by locking the entire map to perform any sort of operation (update,delete,read,create). Suppose we have a web application , the overhead created by Hashtable (locking the entire map) can be ignored under normal load. But under heavy load , the overhead of locking the entire map may prove fatal and may lead to delay response time and overtaxing of the server.
Can two threads update the ConcurrentHashMap simultaneously ? Yes it is possible that two threads can simultaneously write on the ConcurrentHashMap. ConcurrentHashMap default implementation allows 16 threads to read and write in parallel. But in the worst case scenario , when two objects lie in the same segment or same partition, then parallel write would not be possible.
Why ConcurrentHashMap does not allow null keys and null values ? The main reason that nulls aren't allowed in ConcurrentMaps (ConcurrentHashMaps, ConcurrentSkipListMaps) is that ambiguities that may be just barely tolerable in non-concurrent maps can't be accommodated. The main one is that if map.get(key) returns null, you can't detect whether the key explicitly maps to null vs the key isn't mapped. In a non-concurrent map, you can check this via map.contains(key), but in a concurrent one, the map might have changed between calls.
If (map.containsKey(k)) {
return map.get(k);
} else {
throw new KeyNotPresentException();
}
**Why does Java provide default value of partition count as 16 instead of very high value ? ** Ideally, you should choose a value to accommodate as many threads as will ever concurrently modify the table. Using a significantly higher value than you need can waste space and time, and a significantly lower value can lead to thread contention.
Fail Safe and Fail Fast QA Refrences
- https://dzone.com/articles/how-concurrenthashmap-works-internally-in-java
- https://www.burnison.ca/articles/the-concurrency-of-concurrenthashmap
- https://howtodoinjava.com/core-java/multi-threading/best-practices-for-using-concurrenthashmap/
- http://javabypatel.blogspot.com/2016/09/concurrenthashmap-interview-questions.html