Introduction to Components
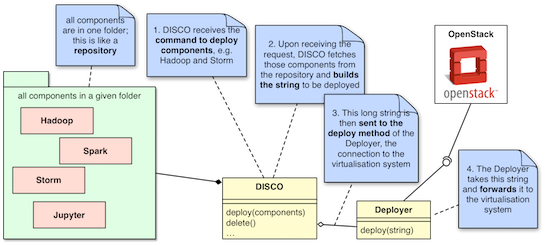
What is a component? In order to understand what a component is, DISCO's processing has to be explained - more concisely, the creation part.
DISCO's output is in every case a string, it doesn't matter whether this string is programming code, a book's chapters, or a Heat template. This string is usually composed of several different parts that are concatenated to a very long string. DISCO then takes this string and submits it to the deploy method of a class Deployer or one of its subclasses.
The question now is: where does DISCO get these substrings from, that are inserted into the long string? This is the part where the components come into play. A component is an entity of one or more files, which are read by DISCO and possibly inserted into the final string. Each component can provide one or multiple of these substrings.
Of course, each component's output can be tailored according to the end user's needs, but that's another topic. Here, another concept of the components shall be mentioned: the one of component states. Each component can have one or more defined states. Let's take the Hadoop component for instance.
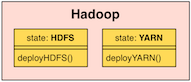
This component has two different states: HDFS and YARN. Both of them can be installed separately; if no resource manager is needed, then the YARN component can just be omitted. (For clarification: in DISCO, Hadoop has only one state and the entire stack is deployed when component Hadoop is requested) At this point, the question might arise why not to deploy two different components for Hadoop instead of one. The answer is simple: HDFS and YARN both are part of Hadoop and should therefore also be treated as one entity.
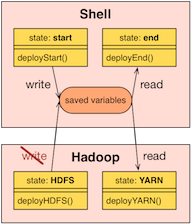
But there is another interesting aspect about states within a component, being the data exchange. If data of any kind is saved within a component, it's much easier to access it from inside the same component than from the outside. Plus: data is only writable from within a component - not from outside.
Resolving required dependencies is one of the major contributions of DISCO for facilitating framework deployment. What does this mean? What it comes down to in the end: you don't need to know which components are needed so that your required component can be installed. Let's take Zeppelin for instance. Zeppelin is a component which provides a Web UI for Spark. If you want to use Zeppelin the "regular" way, you will have to install Spark in order to run Zeppelin. Additionally, you will have to know that Spark requires Java to run, so another component to deploy, and so on. DISCO handles all of this automatically. If you decide to use Zeppelin, DISCO will automatically install the required components, without you even noticing. You can just lean back and wait until the Zeppelin endpoint is accessible. And this is true for any installed component, being it Jupyter, Spark, Hadoop or any future addition. In the following chapters, this whole idea about dependency handling will be explained more clearly.