|
| 1 | +# Model Evaluation |
| 2 | + |
| 3 | +Before deploying a model to be consumed by several applications, |
| 4 | +we need to know what is the expected performance that it will achieve. |
| 5 | +After training a model using the collected and transformed dataset, |
| 6 | +concrete metrics have to be calculated so we can have a vision of |
| 7 | +how well the algorithm can model the data that we have on hand. |
| 8 | + |
| 9 | +Depending on the type of the problem (supervised, unsupervised, |
| 10 | +classification, regression), there are different metrics |
| 11 | +to evaluate. In supervised learning, we have available target values |
| 12 | +that we can use to compare to what was predicted by the model. |
| 13 | +However, the metrics are different between classification and regression problems |
| 14 | +since in the first one the target variable is not continuous. |
| 15 | + |
| 16 | +Another topic worth mentioning, that can lead to misleading conclusions, |
| 17 | +is what data should be used to evaluate. If we train |
| 18 | +the model with the entire dataset, make predictions over the same dataset, |
| 19 | +and compare these predictions with the actual values, we are not |
| 20 | +verifying how the model behaves with unseen data samples. That's why |
| 21 | +before speaking about evaluation metrics, we have to jump into |
| 22 | +data split strategies, to be able to separate the data into |
| 23 | +different sets depending on their use. |
| 24 | + |
| 25 | +## Data Split Strategies |
| 26 | + |
| 27 | +A data split strategy is a way of splitting the data |
| 28 | +into different subsets, so each subset is used with a different goal. |
| 29 | +This will prevent us from using the entire dataset for training, tuning |
| 30 | +, and evaluating which can give false conclusions. |
| 31 | + |
| 32 | +The most used strategies are: |
| 33 | + |
| 34 | +- train-test split |
| 35 | +- cross-validation |
| 36 | +- leave one out |
| 37 | + |
| 38 | +### Train-test split |
| 39 | + |
| 40 | +The idea behind the train-test split, as the name suggests, is to split |
| 41 | +the entire dataset in different sets, usually the following: |
| 42 | + |
| 43 | +- training set (usually ~70%): data samples used to train the model |
| 44 | +- validation set (usually ~15%): data samples used to tune the model |
| 45 | + (hyperparameters, architecture) |
| 46 | +- testing set (usually ~15%): data samples used to evaluate the model |
| 47 | + |
| 48 | +<figure markdown> |
| 49 | + 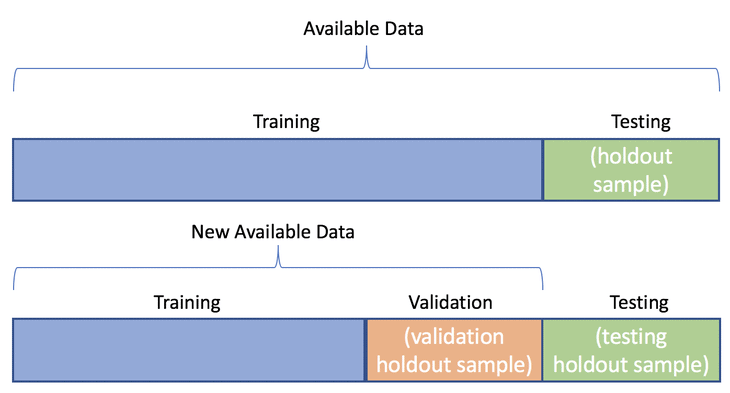{ width="500" } |
| 50 | + <figcaption> |
| 51 | + Train-Test Split. Adapted from "Train/Test Split and Cross Validation – A Python Tutorial” by Greg Bland. |
| 52 | + Retrieved from [here](https://algotrading101.com/learn/train-test-split/). |
| 53 | + </figcaption> |
| 54 | +</figure> |
| 55 | + |
| 56 | +### Cross-validation |
| 57 | + |
| 58 | +Cross-validation, and leave one out are strategies used usually when |
| 59 | +the dataset size is not huge, since they are computationally expensive. |
| 60 | +The idea is to divide the entire dataset into K folds. The model |
| 61 | +will be trained using N - 1 folds and evaluated on the remaining fold. |
| 62 | +These will be performed K (number of folds) times, so the advantage is that |
| 63 | +the data coverage will be higher (more reliable evaluation). |
| 64 | + |
| 65 | +<figure markdown> |
| 66 | + { width="500" } |
| 67 | + <figcaption> |
| 68 | + Cross Validation. Adapted from "Cross-validation: evaluating estimator performance”. |
| 69 | + Retrieved from [here](https://scikit-learn.org/stable/modules/cross_validation.html). |
| 70 | + </figcaption> |
| 71 | +</figure> |
| 72 | + |
| 73 | +### Leave one out |
| 74 | + |
| 75 | +Leave one out is usually applied on small datasets. It is a particular case |
| 76 | +of cross-validation, it is equivalent to using cross-validation with |
| 77 | +N folds, given that N is the number of samples in the dataset. |
| 78 | +This means that the model will be trained and evaluated N times, |
| 79 | +and the prediction for evaluation will be performed on a single |
| 80 | +sample at a time. |
| 81 | + |
| 82 | +### To be aware |
| 83 | + |
| 84 | +It is worth mentioning two additional topics: |
| 85 | + |
| 86 | +- temporal data: when dealing with temporal data, it is |
| 87 | + important to sort before applying the split, because |
| 88 | + it is considered "cheating" if the sort operation |
| 89 | + is not applied. Imagine having past and future samples |
| 90 | + in the training set of a sample in the test set. This |
| 91 | + would not reflect the real usage of the model; |
| 92 | + |
| 93 | +- stratification: in classification problems, it is important |
| 94 | + to maintain the class distribution along the different sets, |
| 95 | + so we can avoid having, for example, a test set with samples |
| 96 | + of a single class. |
| 97 | + |
| 98 | +## Evaluation Metrics |
| 99 | + |
| 100 | +Evaluation metrics can be divided into regression and classification |
| 101 | +since the output is different depending on the type of the problem. |
| 102 | +However, the goal of these metrics is to evaluate how well the model |
| 103 | +can make predictions. It receives as input the actuals (y) and |
| 104 | +the predicted values for the same samples (ŷ). |
| 105 | + |
| 106 | +### Regression |
| 107 | + |
| 108 | +In regression, the actuals and the predicted values are continuous. |
| 109 | +The following metrics are usually used to evaluate this kind of models: |
| 110 | + |
| 111 | +- Mean Absolute Error (MAE) |
| 112 | + |
| 113 | +MAE is the easiest metric to interpret. It represents how much |
| 114 | +the predicted value deviates from the actual value. n is the number |
| 115 | +of samples (size of y and ŷ). |
| 116 | + |
| 117 | +`MAE = (1/n) * Σ|yi - ŷi|` |
| 118 | + |
| 119 | +- Mean Square Error (MSE) |
| 120 | + |
| 121 | +MSE is very similar to MAE. The difference is that it is squared instead |
| 122 | +of using the absolute difference. This will penalize |
| 123 | +higher errors. It is usually used as a loss function in some of the |
| 124 | +models (i.e Neural Network). |
| 125 | + |
| 126 | +`MSE = (1/n) * Σ(yi - ŷi)²` |
| 127 | + |
| 128 | +- Root Mean Square Error (RMSE) |
| 129 | + |
| 130 | +RMSE is the root of MSE. This facilitates the interpretation |
| 131 | +since it converts the unit from squared to the original unit. |
| 132 | + |
| 133 | +`RMSE = sqrt((1/n) * Σ(yi - ŷi)²)` |
| 134 | + |
| 135 | +- R-Squared Score (R2) |
| 136 | + |
| 137 | +R2 is a metric that represents how much variance of the data |
| 138 | +was successfully modeled. It indicates how well the model |
| 139 | +could represent the data and can establish a relationship |
| 140 | +between the independent variables and the dependent variable. |
| 141 | + |
| 142 | +SSres is the residual sum of squares, and SStot is the |
| 143 | +total variance contained in the target output y. This metric is |
| 144 | +within the range of 0.0 to 1.0, being 1.0 a perfect model, able to |
| 145 | +represent the entire variance. It can also have negative values |
| 146 | +in cases where there is a terrible relationship between the |
| 147 | +target and independent variables. |
| 148 | + |
| 149 | +`R2 = 1 - (SSres / SStot)` |
| 150 | + |
| 151 | +## Useful Plots |
| 152 | + |
| 153 | +Visualization sometimes can help taking conclusions about the |
| 154 | +obtained results. The listed metrics in the previous section |
| 155 | +are good to have a clear and specific evaluation of the model. |
| 156 | +However, some useful plots can be visualized to |
| 157 | +complement the achieved numeric results. |
| 158 | + |
| 159 | +### Regression |
| 160 | + |
| 161 | +The first plot is the actuals vs predicted values. |
| 162 | +Ideally, all the points should be laid in the diagonal line, |
| 163 | +which represents that the predicted value is equal to the |
| 164 | +actual value. This plot gives an overall idea of the |
| 165 | +achieved predictions and how far they are from the actual value. |
| 166 | + |
| 167 | +<figure markdown> |
| 168 | + { width="400" } |
| 169 | + <figcaption> |
| 170 | + Actual vs Predicted plot. |
| 171 | + Retrieved from [here](https://stats.stackexchange.com/questions/333037/interpret-regression-model-actual-vs-predicted-plot-far-off-of-y-x-line). |
| 172 | + </figcaption> |
| 173 | +</figure> |
| 174 | + |
| 175 | +The second one is similar, however, the residual value |
| 176 | +substitutes one of the previous variables (actuals or predictions). |
| 177 | +Ideally, the points should be near 0.0 which means no error. |
| 178 | +The goal of this plot is to conclude the error for each |
| 179 | +range of values and visualize possible trends that the errors |
| 180 | +may show. This indicates that there is some pattern contained in |
| 181 | +the data that the model was not able to cover. |
| 182 | + |
| 183 | +<figure markdown> |
| 184 | + 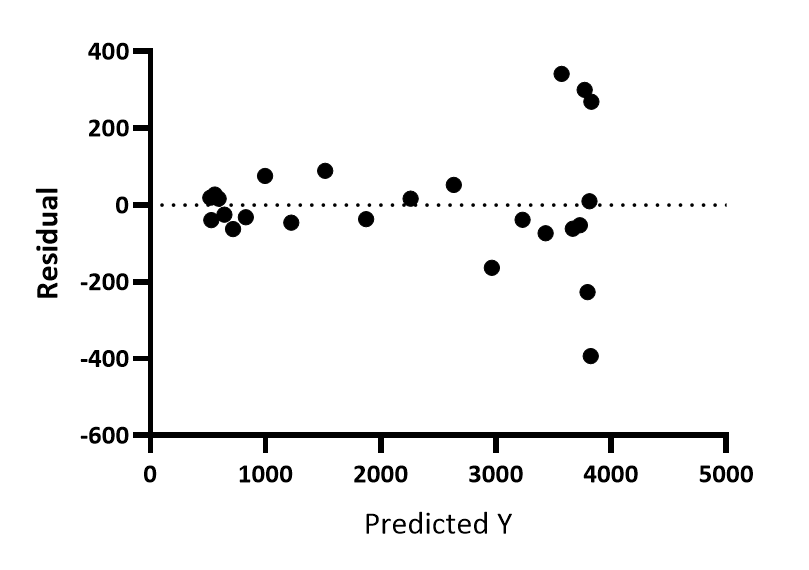{ width="400" } |
| 185 | + <figcaption> |
| 186 | + Residuals vs Predicted plot. Adapted from "Residual plot". |
| 187 | + Retrieved from [here](https://www.graphpad.com/guides/prism/latest/curve-fitting/reg_fit_tab_residuals_2.htm). |
| 188 | + </figcaption> |
| 189 | +</figure> |
| 190 | + |
| 191 | +The last one is the histogram of residuals. This allows the |
| 192 | +conclusion of where are most errors contained. Additionally, |
| 193 | +it is also important to conclude the distribution of the errors. |
| 194 | +For example, a Linear Regression assumes that the errors are normally |
| 195 | +distributed. |
| 196 | + |
| 197 | +<figure markdown> |
| 198 | + 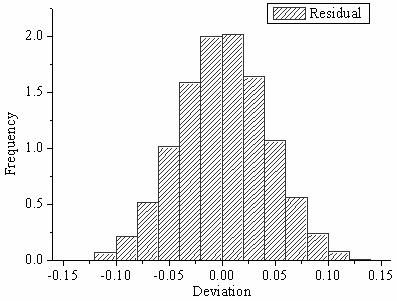{ width="400" } |
| 199 | + <figcaption> |
| 200 | + Residuals Histogram. Adapted from "Residual Plot Analysis”. |
| 201 | + Retrieved from [here](https://www.originlab.com/doc/origin-help/residual-plot-analysis). |
| 202 | + </figcaption> |
| 203 | +</figure> |
0 commit comments