
Static файлы - файлы, которые не являются частью обязательных файлов для работы системы ( *.py, *.html), но
необходимы для изменения отображения (*.css, *.js, *.jpg). К таким файлам есть доступ из кода, и обычно они не
могут быть изменены с пользовательской стороны (шрифты на сайте, css стили, картинка на фоне и т.д.)
Media файлы - файлы, загруженные пользователями (вне зависимости от привилегий), например, аватарки, картинки товаров, голосовые сообщения :) К таким файлам в репозитории нет и не должно быть доступа.
Static файлы практически всегда разбросаны по приложениям проекта, что очень удобно при разработке, но при использовании их гораздо проще хранить в одном месте, и тоже вне проекта.
Media файлы нужно хранить отдельно от статики, иначе можно получить большое количество проблем.
Проще всего создать две отдельные папки static и media или одну папку files, а в ней уже вложенные папки static
и media.
В рамках Django при создании проекта в начальной версии setting.py в INSTALLED_APPS автоматически
добавляется django.contrib.staticfiles, именно это приложение отвечает за то, как будут обрабатываться статические
файлы.
# settings.py
STATIC_URL = '/static/'Указанный параметр STATIC_URL будет преобразован в URL, по которому можно получить статические файлы.
Например, "/static/" или "http://static.example.com/"
В первом случае при запросе к статике будет выполнен запрос на текущий URL с приставкой http://127.0.0.1:8000/static/
Во втором запросы будут произведены на отдельный URL.
В шаблоне, где мы можем использовать template tag static:
{% load static %}
<img src="{% static 'my_app/example.jpg' %}" alt="My image">В settings.py есть переменная DEBUG, по дефолту она равна True, но за что она отвечает?
В основном она отвечает за то, как вести себя при ошибках (чаще всего 500-х). Если вы делаете неправильный запрос (не
туда, не те данные и т.д.), то вы видите подробное описание того, почему ваш запрос не удался, на какой строчке кода
упал, или нет такого URL, но вот такие есть. Всё это отображается только потому, что переменная DEBUG=True.
Запущенный сайт никогда не покажет вам эту информацию.
На самом деле, если у вас DEBUG=True и вы запускаете команду runserver, то запускается еще
и django.contrib.staticfiles.views.serve(), который позволяет отображать статические файлы в процессе разработки. При
загрузке проекта в реальное использование переменную DEBUG нужно установить в False и обрабатывать статические
файлы внешними средствами, поговорим о них ниже.
Список папок, в которых хранится ваша статика для разработки, чаще всего это папки static в разных приложениях,
например, authenticate/static, billing/static и т.д.
НЕ ДОЛЖЕН СОДЕРЖАТЬ ЗНАЧЕНИЕ ИЗ ПЕРЕМЕННОЙ STATIC_ROOT!!!!
Переменная, содержащая путь к папке, в которую всю найденную статику из папок в переменной STATICFILES_DIRS
соберёт команда python manage.py collectstatic.
Как это работает на практике? При разработке используются статические файлы из папок разных приложений, а для
продакшена настраивается скрипт, который при любом изменении будет запускать команду collectstatic, которая будет
собирать всю статику в то место, которое уже обрабатывается сторонними сервисами, о которых ниже.
По аналогии со статикой такая же настройка для медиа.
Абсолютный путь к папке, в которой мы будем хранить пользовательские файлы.
Медиа собирать не нужно, так как мы не можем её менять, это только пользовательская привилегия.
Что такое деплой? Это развертывание вашего проекта для использования его из интернета, а не локально.
Что для этого необходимо? Нужен сервер (на самом деле, им может быть любое устройство: комп, телефон и т.д.), но у сервера есть одна особенность, ему нужно работать всегда, мы же не хотим, чтобы наш сайт или приложение переставало работать.
Чтобы организовать 100% uptime, чаще всего используются облачные сервера, многие компании готовы предоставить такие сервера на платной основе. Мой личный опыт говорит о том, что самые надёжные и самые часто используемые - это сервера компании Amazon, также у Amazon очень большая инфраструктура и экосистема для обслуживания сервером, но об этом в следующий раз.
Сервис, который предоставляет нам выделенные мощности, называется EC2.
Для начала нам необходим аккаунт на платформе AWS (Amazon Web Services).
У Amazon существуют сотни различных сервисов для различных задач, но на данном этапе нас интересует только EC2.
EC2 - это сервис, который позволяет запускать виртуальные сервера с различной мощностью на различных операционных системах.
Для нашего случая мы будем рассматривать самый слабый по характеристикам сервер (t2.nano) на базе Linux (Ubuntu Server 18.04 LTS).
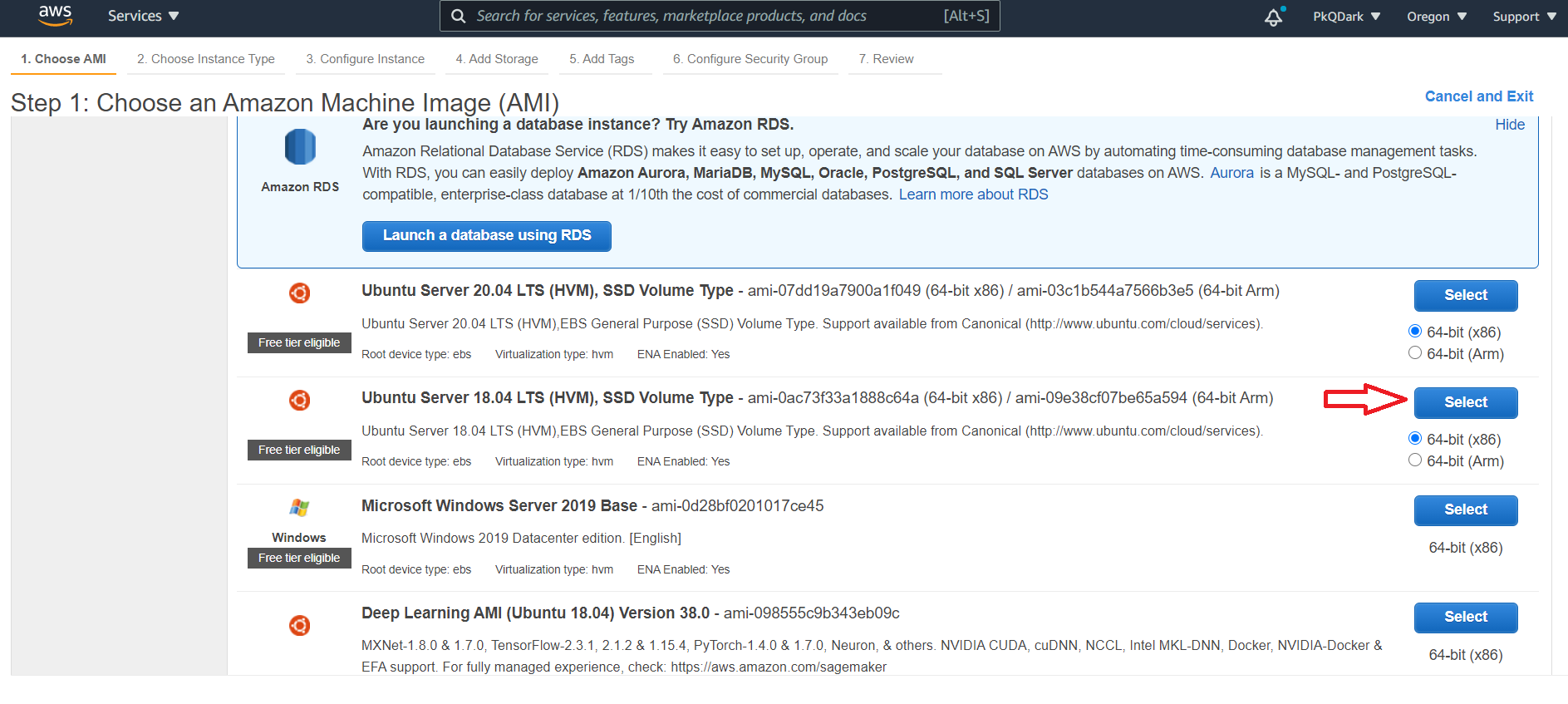
На следующей вкладке выбираем мощность сервера и пару ключей для подключения по SSH.
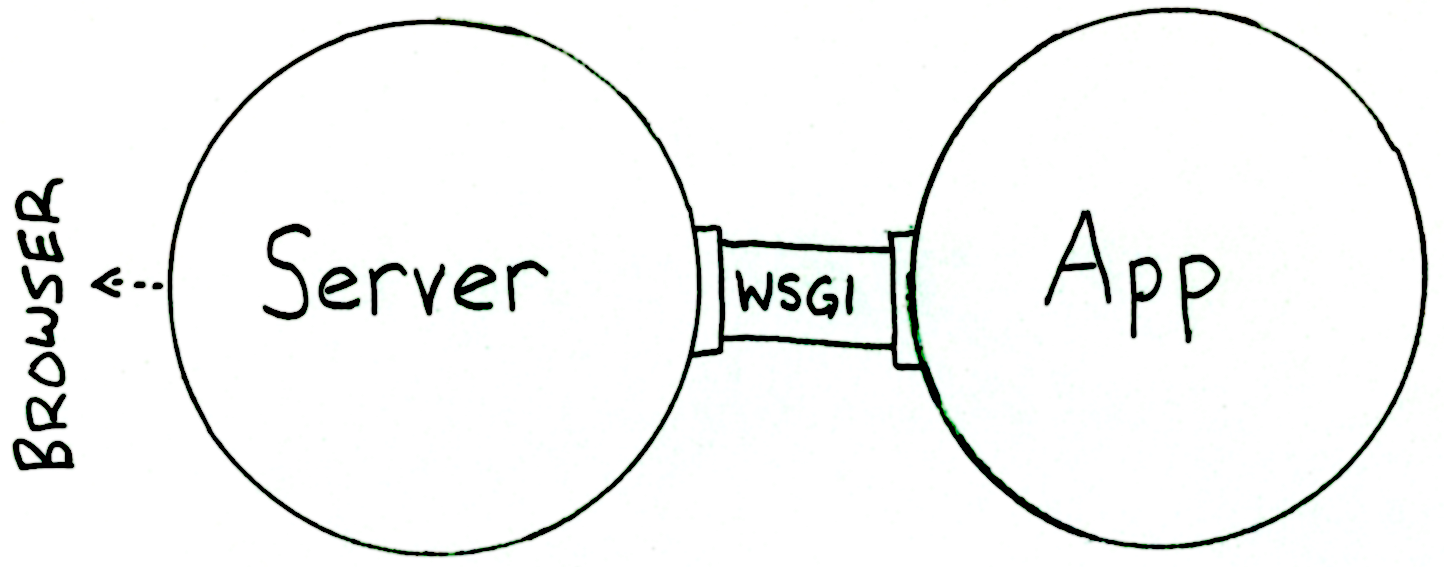
Для деплоя Django приложения используется два различных сервера, первый - для запуска приложения локально на сервере, второй - как прокси, чтобы выход в интернет связать с этим локально запущенным сервером и предоставить доступ к статике и медиа. За обработку данных будет отвечать первый сервер, за безопасность и распределение нагрузок - второй.
Первый сервер - это WSGI (Web-Server Gateway Interface), работает примерно так:
В качестве WSGI сервера может быть использовано достаточно большое количество разных серверов:
- uWSGI
- Bjoern
- uWSGI
- mod_wsgi
- Meinheld
- Gunicorn
И так далее, это далеко не полный список. В качестве примера мы будем использовать Gunicorn (на моей практике самый используемый сервер).
Также существует технология ASGI (Asynchronous Standard Gateway Interface) - это улучшение технологии WSGI, основные серверы для ASGI:
- Daphne
- Hypercorn
- Uvicorn
Тоже часто используемые технологии, и скорее всего дальше будут использоваться всё чаще.
В качестве прокси сервера могут быть использованы:
- Nginx
- Apache
Может возникнуть идея, а почему бы не использовать команду runserver? Зачем нам вообще какие-то дополнительные
сервера? Команда runserver не предполагает даже относительно серьезных нагрузок, даже при условных 100 пользователях
базовая команда будет захлёбываться.
Рассмотрим, как развернуть наш проект на примере EC2 (Ubuntu 18.04) + Gunicorn + Nginx
Для начала необходимо зайти на наш EC2 сервер при помощи SSH.
Если вы используете Windows, то самый простой способ использовать SSH - это либо клиент putty, либо установить Git CLI,
git интерфейс поддерживает команду ssh.
Свежесозданный инстанс не содержит вообще ничего, даже интерпретатора Python, а значит, нам необходимо его установить, но вместе с ним установим и другие нужные пакеты (БД, сервера и т.д.).
sudo apt update
sudo apt install python3-pip python3-dev python3-venv libpq-dev postgresql postgresql-contrib nginx curl
Как создать базу данных и пользователя с доступом к ней, вы уже знаете, заходим в консоль postgresql и делаем это:
sudo -u postgres psql
User: myuser
DB: mydb
password: mypass
Чтобы вносить некоторые параметры в код, используются переменные операционной системы, допустим, в файле settings.py
мы можем хранить пароль от базы данных, ключи от сервисов и много другой информации, которую нельзя разглашать, но в
случае, если вы оставите эти данные в коде, они попадут на git, этого допускать нельзя.
Для использования переменных в ОС Linux используется команда export var_name="value"
Если просто в консоль внести команду экспорта, она обнулится после перезагрузки инстанса, нас это не устраивает,
поэтому экспорт переменных нужно вносить в файл, загружаемый при каждом запуске, например, ~/.bashrc, открываем
sudo nano ~/.bashrc и в самом конце дописываем:
export PROD='True';
export DBNAME='mydb';
export DBUSER='myuser';
export DBPASS='mypass';
Не забываем выполнить source, чтобы применить эти изменения.
Для gunicorn проще занести все переменные в отдельный файл, и мы будем использовать его в дальнейшем, создадим еще один файл с этими же переменными.
sudo nano /home/ubuntu/.env
PROD='True'
DBNAME='mydb'
DBUSER='myuser'
DBPASS='mypass'
Один из удобных способов разделить настройки на локальные и продакшен - это всё те же переменные операционной системы,
например, добавить в проект на уровне файла settings.py еще два файла settings_prod.py и settings_local.py, в
основной файл нужно импортировать модуль os и в конце дописать:
if os.environ.get('PROD'):
try:
from .settings_prod import *
except ImportError:
pass
else:
try:
from .settings_local import *
except ImportError:
passТаким образом мы сможем разделить настройки в зависимости от того, есть ли в операционной системе переменная PROD.
В settings_prod.py укажем:
import os
DEBUG = False
ALLOWED_HOSTS = ['54.186.155.252']
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql',
'NAME': os.environ.get('DBNAME'),
'USER': os.environ.get('DBUSER'),
'PASSWORD': os.environ.get('DBPASS'),
'HOST': os.environ.get('DBHOST', '127.0.0.1'),
'PORT': os.environ.get('DBPORT', '5432'),
}
}Параметр DEBUG = False , так как нам не нужно отображать подробности ошибок.
В ALLOWED_HOSTS нужно указывать URL и/или IP, по которому будет доступно приложение. Как указать там URL, мы поговорим
на следующем занятии, а пока можно указать там IP, который мы получили у Amazon после создания инстанса:
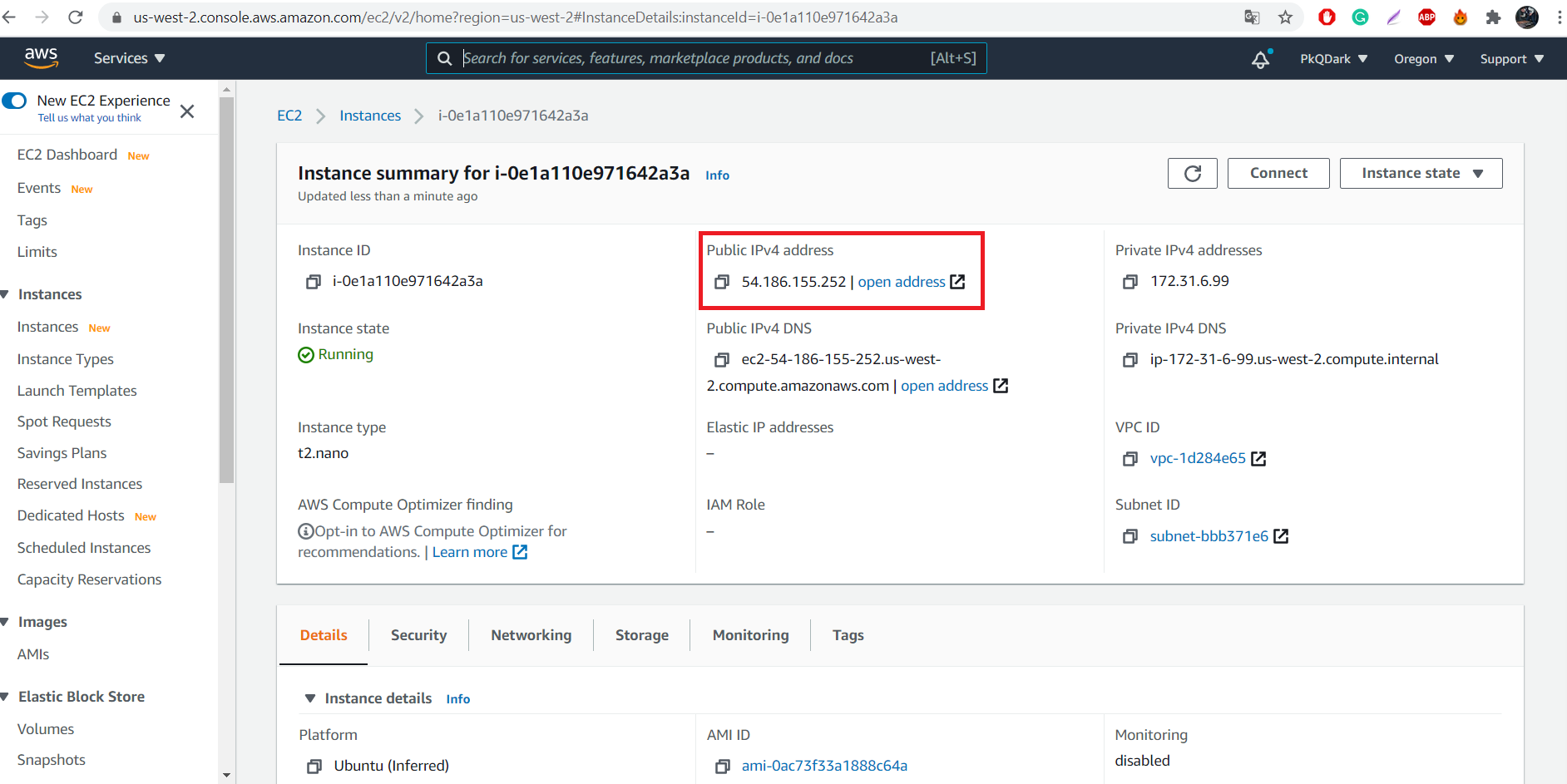
Клонируем код нашего проекта:
git clone https://github.com/your-git/your-repo.git
Создаём виртуальное окружение, я обычно создаю отдельную папку в рабочей папке:
cd ~/
mkdir venv
python3 -m venv venv/
И активируем его:
source ~/venv/bin/activate
Переходим в раздел с проектом и устанавливаем всё, что есть в requirements.txt:
cd ~/proj_name
pip install -r requirements.txt
Если локально вы не работали с базой postgresql, то необходимо доставить модуль для работы с ним:
pip install psycopg2-binary
После чего вы должны успешно применить миграции:
python manage.py migrate
Для проверки того, что ваше приложение можно разворачивать, запустим его через стандартную команду:
python manage.py runserver
Чтобы это сработало, необходимо разрешить использовать порт, который мы будем использовать для теста, по стандарту это порт номер 8000:
sudo ufw allow 8000
Мы открыли порт со стороны сервера, но пока что он закрыт со стороны Amazon, давайте временно откроем его тоже. Для
этого идём на страницу Amazon с описанием инстанса, открываем вкладку Security и кликаем на название секьюрити группы:
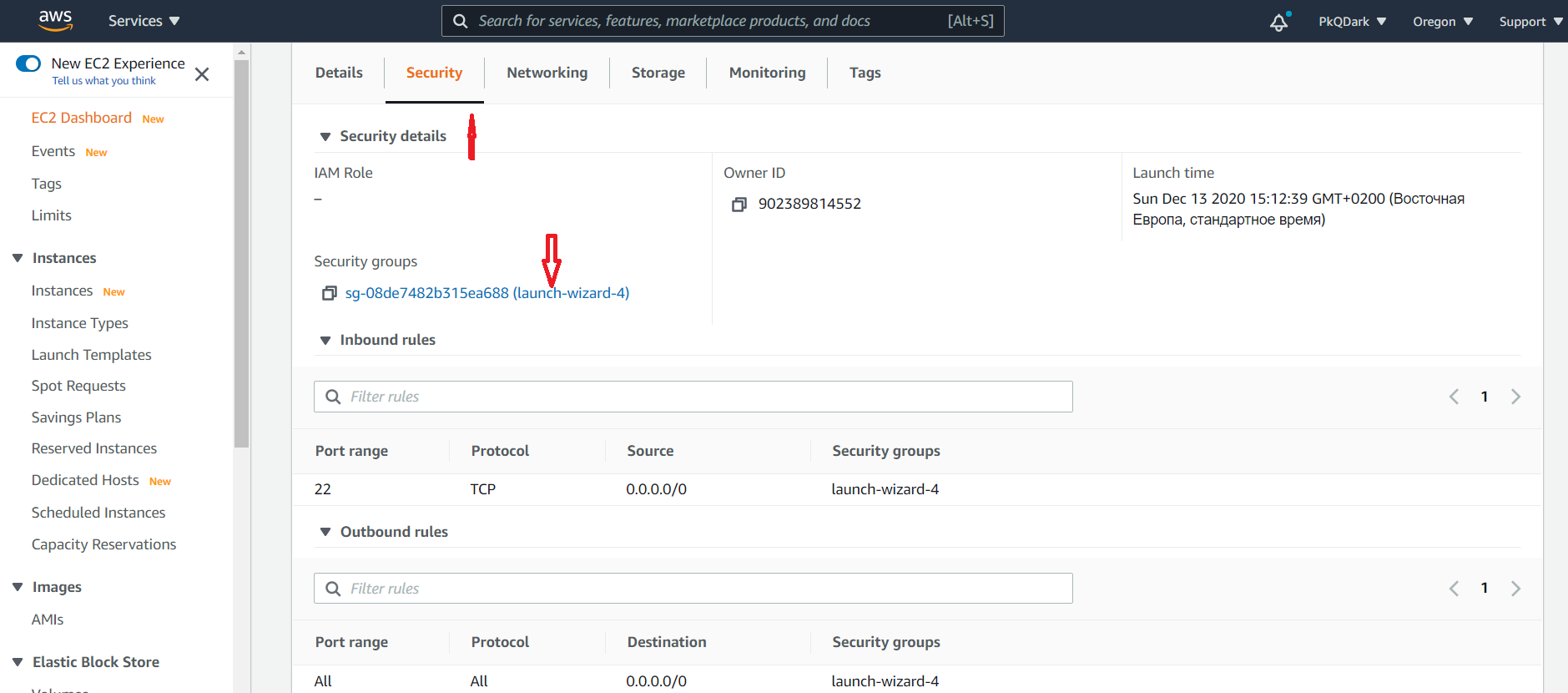
Кликаем на Edit inbound rules.
Добавляем правило Custom TCP для порта 8000:
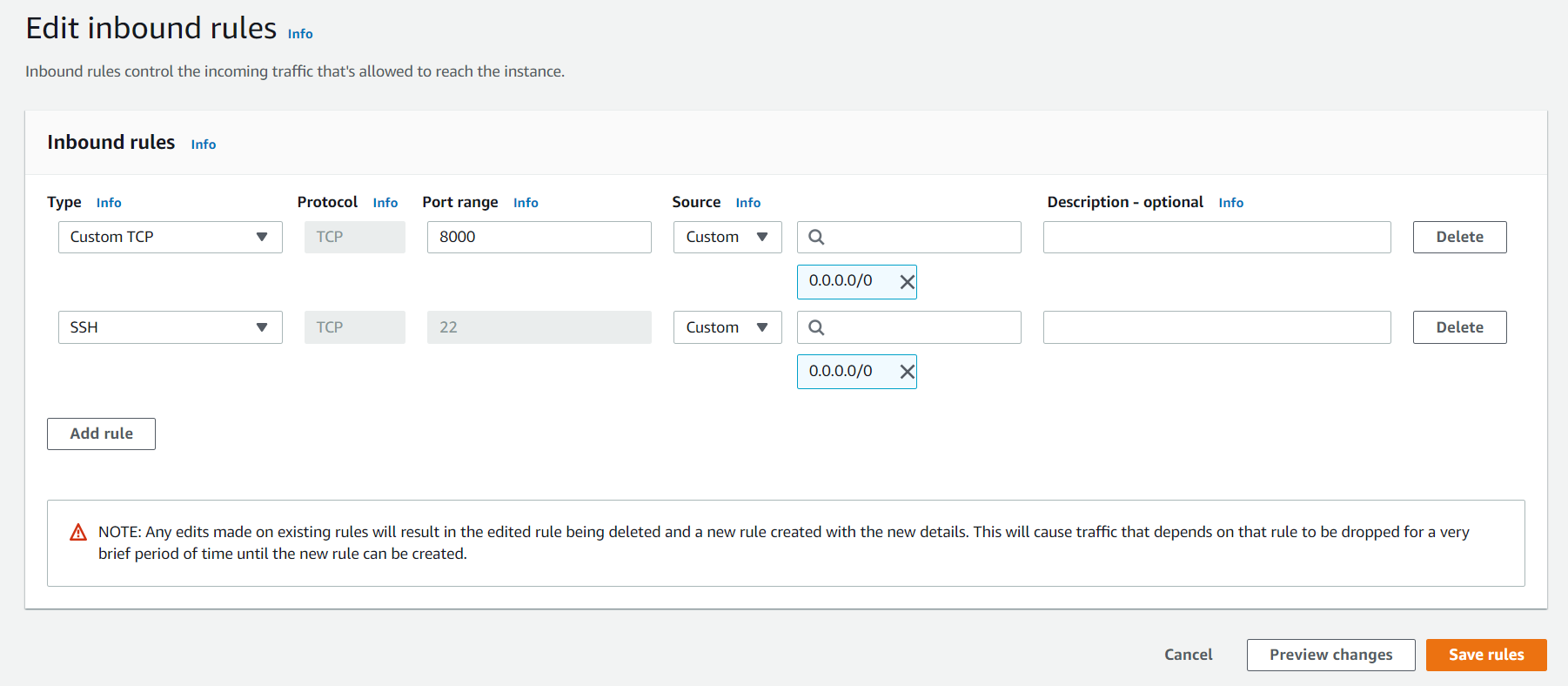
После этого можно запустить команду runserver с такими правилами:
python manage.py runserver 0.0.0.0:8000
Если вы всё сделали правильно, то теперь вы можете открыть в браузере IP адрес, который вам выдал Amazon, с портом 8000:
# Например
http://54.186.155.252:8000/
Обратите внимание, сайт откроется БЕЗ СТАТИКИ, потому что runserver при DEBUG = False не должен обрабатывать
статику.
Устанавливаем gunicorn
pip install gunicorn
Как вы помните, gunicorn - это WSGI сервер. Если вы откроете папку с settings.py, то вы увидите там еще два
файла wsgi.py и asgi.py.
Они нужны для того, чтобы запускать сервера в "боевом" режиме.
Для проверки работы gunicorn запустим сервер через него:
gunicorn --bind 0.0.0.0: 8000 Proj.wsgi
Где Proj - это название папки, в котором лежит файл wsgi.py.
Опять же, если вы всё сделали правильно, то тот же самый URL всё ещё будет работать.
# Например
http://54.186.155.252:8000/
В Linux абсолютно всё - это файл. Развёрнутый сервер - это тоже файл. Так вот, если мы используем два сервера, и один слушает второй, то давайте разворачивать первый тоже как файл. Такой файл будет называться сокет-файлом.
Запускать сервер руками очень увлекательно, но не очень эффективно, давайте демонизируем gunicorn для запуска сервера в сокет-файл, и сделаем так, чтобы этот сервер запускался сразу при запуске системы, чтобы даже если мы перезагрузим инстанс, сервер всё равно работал.
Воспользуемся встроенной в Linux системой systemd (системная демонизация).
Создадим системный файл для описания сокета:
sudo nano /etc/systemd/system/gunicorn.socket
#/etc/systemd/system/gunicorn.socket
[Unit]
Description=gunicorn socket
[Socket]
ListenStream=/home/ubuntu/proj/run/gunicorn.sock
[Install]
WantedBy=sockets.target
Блок Unit отвечает за описание демона.
Блок Socket отвечает за то, где будет находиться файл сокета, proj в данном случае - название папки с проектом,
run - название папки с файлом сокета (так почему-то принято называть).
Блок Install отвечает за автоматический запуск при запуске системы.
Сохраните файл и закройте его.
Теперь нужно создать файл сервиса, который и будет выполнять запуск:
sudo nano /etc/systemd/system/gunicorn.service
Названия сервиса и сокета должны совпадать:
[Unit]
Description=gunicorn daemon
Requires=gunicorn.socket
After=network.target
[Service]
User=ubuntu
Group=www-data
WorkingDirectory=/home/ubuntu/myprojectdir
EnvironmentFile=/home/ubuntu/.env
ExecStart=/home/ubuntu/venv/bin/gunicorn \
--access-logfile - \
--workers 3 \
--bind unix:/home/ubuntu/myprojectdir/run/gunicorn.sock \
myproject.wsgi:application
[Install]
WantedBy=multi-user.target
Блок Unit:
Description- описание.Requires- связывает сервис с сокетом.After- отвечает за то, чтобы запускать модуль только после того, как будет доступ в интернет.
Блок Service:
-
User- пользователь, который должен запускать скрипт, если мы используем стандартного юзера, то это будетubuntu. -
Group- группа безопасности, по дефолту - этоwww-data. -
WorkingDirectory- папка, из которой будет запускаться скрипт, в нашем случае это папка с проектом, где лежитmanage.py. -
EnvironmentFile- файл с переменными. -
ExecStart- сам скрипт, нам нужно запустить gunicorn из виртуального окружения, но мы не можем запустить сначалаsource, но при создании виртуального окружения, мы всего-то складываем все скрипты в другую папку./home/ubuntu/venv/bin/gunicorn- это физическое расположение скрипта--access-logfile - --workers 3 --bind unix:/home/ubuntu/myprojectdir/run/gunicorn.sock myproject.wsgi:applicationЭто настройки самого скрипта,log level- это место для записи логов,worker- их количество,bind- место, куда сложить файл (unix: значит, что будет файл),myproject- название папки, где лежитwsgi.py
Блок Install отвечает за автоматический запуск при запуске системы для любого пользователя.
Сохраняем файл и закрываем.
Для запуска сокета нужно запустить его из системы:
sudo systemctl start gunicorn.socket
sudo systemctl enable gunicorn.socket
В следующий раз этого делать не нужно, всё запустится автоматически.
sudo systemctl status gunicorn.socket
Если тут мы не видим никаких ошибок, то нужно проверить наличие файла сокета. Если всё есть, то создание сокета работает.
Проверим его активацию:
sudo systemctl status gunicorn
Должны увидеть примерно такой статус:
gunicorn.service - gunicorn daemon
Loaded: loaded (/etc/systemd/system/gunicorn.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Попробуем выполнить запрос к нашему сокету:
curl --unix-socket /home/ubuntu/proj/run/gunicorn.sock localhost
И проверим статус еще раз, теперь он будет active
Теперь мы можем перезапускать наш сокет за 1 команду:
sudo systemctl restart gunicorn
Nginx - это веб сервер, гибкий и мощный веб-сервер.
Для проверки работы Nginx давайте настроим базовый доступ к Nginx для нашего IP адреса, и не забываем добавить 80 порт в секьюрити группы Amazon.
Настроим Nginx, если вы установили Nginx (мы сделали это первым действием на этом инстансе), то у вас будет существовать папка с базовыми настройками Nginx, давайте создадим новую настройку:
sudo nano /etc/nginx/sites-available/myproject
Где myproject - это название вашего проекта.
server {
listen 80;
server_name 54.186.155.252;
}
Сохранить и закрыть, пробросить симлинк в соседнюю папку, которую по дефолту обслуживает Nginx:
sudo ln -s /etc/nginx/sites-available/myproject /etc/nginx/sites-enabled/
ОБЯЗАТЕЛЬНО! Добавить 80 порт в security groups, разрешенные на Amazon!!!
Если вы всё сделали правильно, то по вашему IP адресу без указания порта будет открыта базовая страница Nginx:
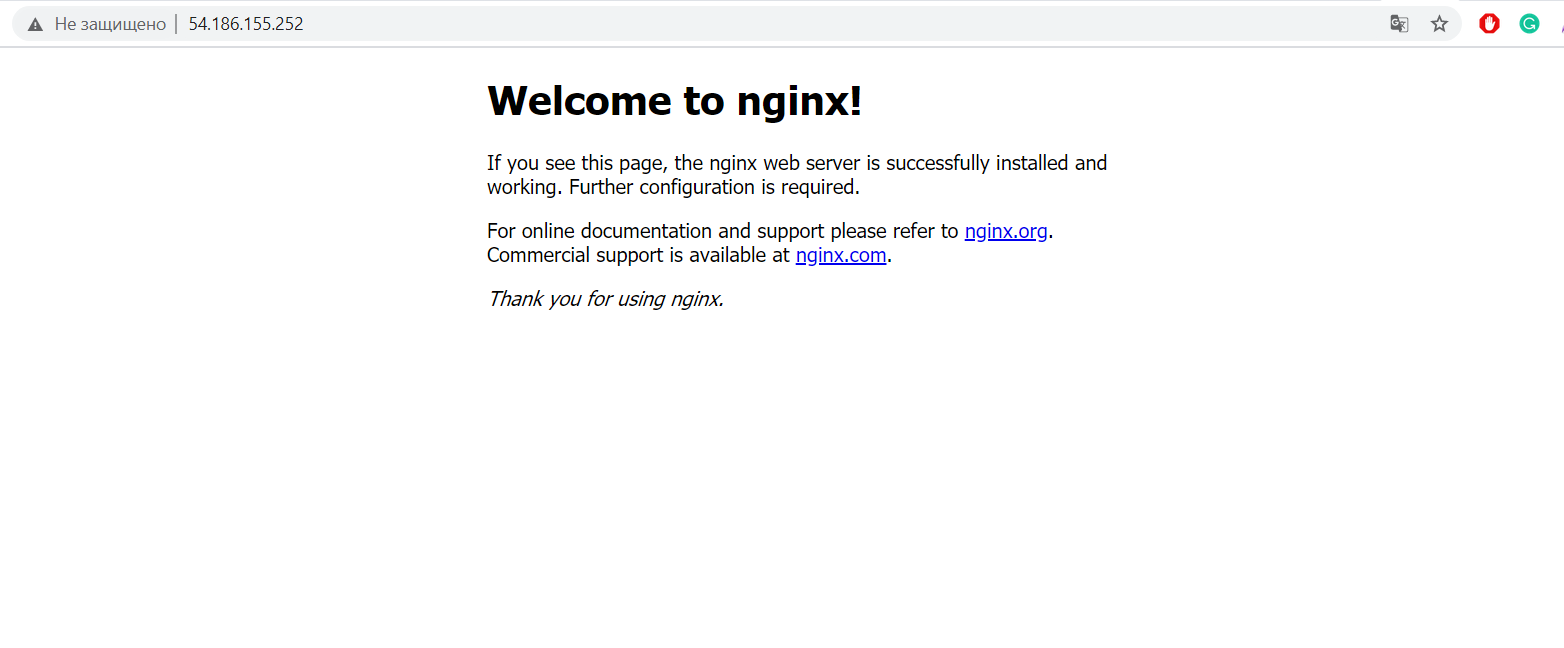
Чтобы Nginx начал проксировать наш проект, нужно его указать:
sudo nano /etc/nginx/sites-available/myproject
server {
listen 80;
server_name some_IP_or_url;
location / {
include proxy_params;
proxy_pass http://unix:/home/ubuntu/path/to/my/socket/gunicorn.sock;
}
}
Перезапускаем Nginx и проверяем:
sudo systemctl restart nginx
Всё должно работать, но без статики.
Вспомним самое начало лекции, что мы можем придумать куда команда collectstatic должна сложить статику. Запускаем
команду и указываем Nginx, что нужно обрабатывать статику и медиа.
server {
listen 80;
server_name 34.221.249.152;
location /static/ {
root /home/ubuntu/deployment;
}
location /media/ {
root /home/ubuntu/deployment;
}
location / {
include proxy_params;
proxy_pass http://unix:/home/ubuntu/path/to/my/socket/gunicorn.sock;
}
}
Перезапускаем Nginx и наслаждаемся результатом!
Не забываем закрыть 8000 порт и на инстансе, и на Amazon в секьюрити группе!!
sudo ufw delete allow 8000
Amazon - это не только инстансы, это огромная, нет ОГРОМНАЯ экосистема из очень большого количества различных сервисов, которые мы можем использовать для своих нужд, там есть почти всё :) даже генераторы нейросетей.
Нас на данном этапе интересует несколько сервисов:
-
RDS (Relational Database Service) - сервис по использованию SQL баз данных, которые будут находиться на Amazon. Зачем это нужно? Во-первых, это надёжно. Мы уверены, что БД находится в облаке, мы за неё платим и Amazon гарантирует её сохранность. В случае хранения БД на инстансе, БД в случае чего удалится вместе с инстансом. Во-вторых, в случае микросервисной архитектуры микросервисы физически могут находиться на совершенно разных машинах, а требуется использовать одну и ту же БД. Облачная БД - лучший для этого выбор. В-третьих, при использовании Amazon RDS не требуется настраивать систему резервных копий, она уже предоставлена экосистемой Amazon в несколько кликов.
-
S3 Bucket - это просто хранилище для файлов. Используется для адекватного хранения статики и медиа. Преимущества очень похожи на RDS. Во-первых, мы не потеряем данные статики и медиа в случае "переезда" на новый сервер. Во-вторых, пользовательские медиа могут занимать огромные объемы данных (например, видеофайлы). В случае хранения их на выделенном сервере мы упираемся в размер сервера (чем больше, тем дороже), а расширять сервер только для "картинок и видео" не очень разумно. Стоимость S3 Bucket гораздо меньше и удобнее для этих целей. В-третьих, безопасность, когда вы складываете статику и медиа у себя, доступ к ним есть у всех пользователей. Кто угодно может открыть наш JS почитать, это не очень безопасно, вдруг у нас там дыры. :) С медиа всё еще хуже, это пользовательские данные, а мы выставляем их на всеобщее обозрение. Это не очень правильно. При использовании S3 Bucket мы можем настроить безопасность, создать пользователя в сервисе IAM (о неё дальше). Django из коробки умеет добавлять безопасный токен при использовании Amazon.
-
IAM - сервис для настроек безопасности. Всё на самом деле просто, там можно создать юзеров и группы юзеров, и раздать им права на любые сервисы Amazon. Допустим, одна группа может только настраивать RDS и смотреть на EC2, а другая обладает полными правами. В нашем случае мы будем создавать пользователя с правами на чтение S3 Bucket и использовать его credentials для статики и медиа.
-
Route 53 - сервис для настройки DNS и регистрации доменов, будем использовать его для того, чтобы купить домен и преобразовать наш IP в нормальный URL.
Мы будем использовать PostgreSQL.
При создании БД вам будет предложено создать мастер пароль для пользователя postgres, его надо запомнить :)
После создания базы данных нужно открыть подробности и раздел Connectivity & security:
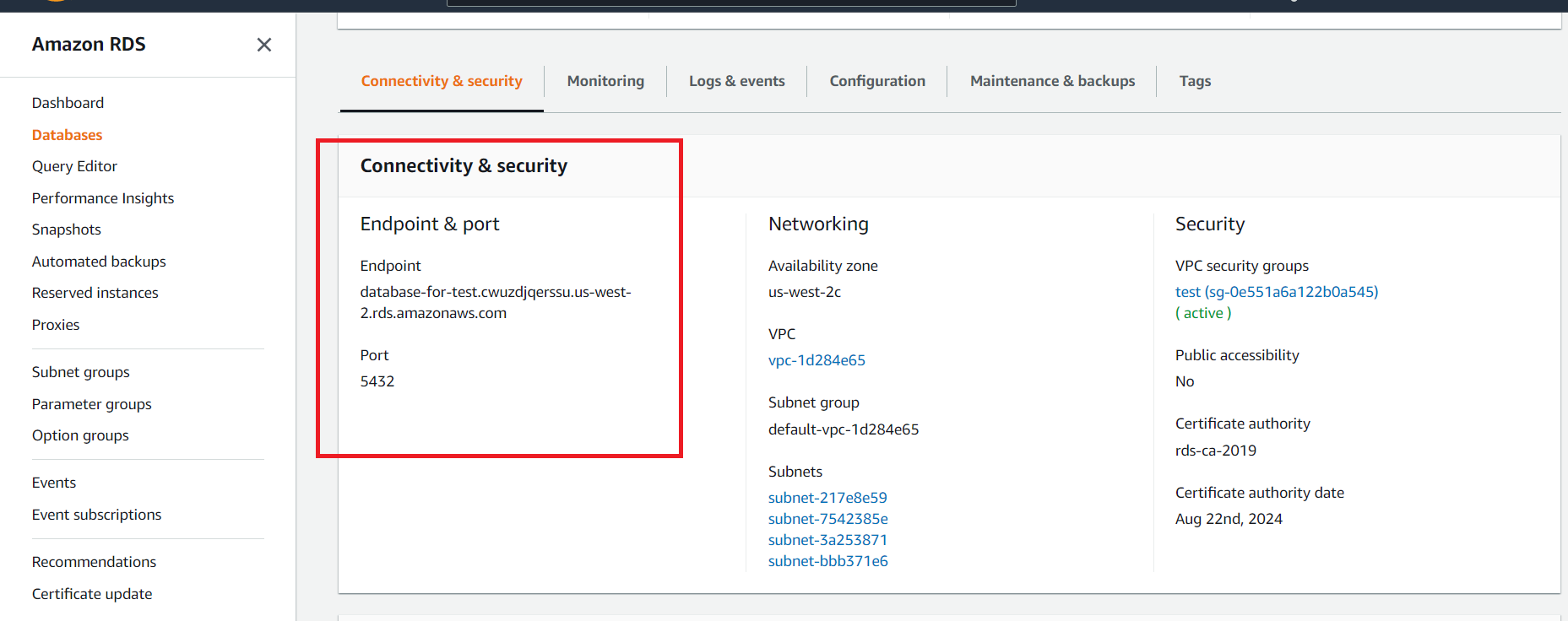
После чего мы можем открыть PostgreSQL консоль из консоли нашего инстанса:
psql --host=<DB instance endpoint> --port=<port> --username=<master username> --password
Создаём пользователя и базу, мы это уже умеем делать.
Допустим, у нас опять user - myuser, password - mypass, db - mydb;
Как подключить RDS к приложению? Добавляем URL в переменные окружения, и база будет подключена.
Не забываем провести миграции, мы подключили новую базу!
Для использования S3 Bucket нам необходим специальный юзер, которого мы можем создать в IAM
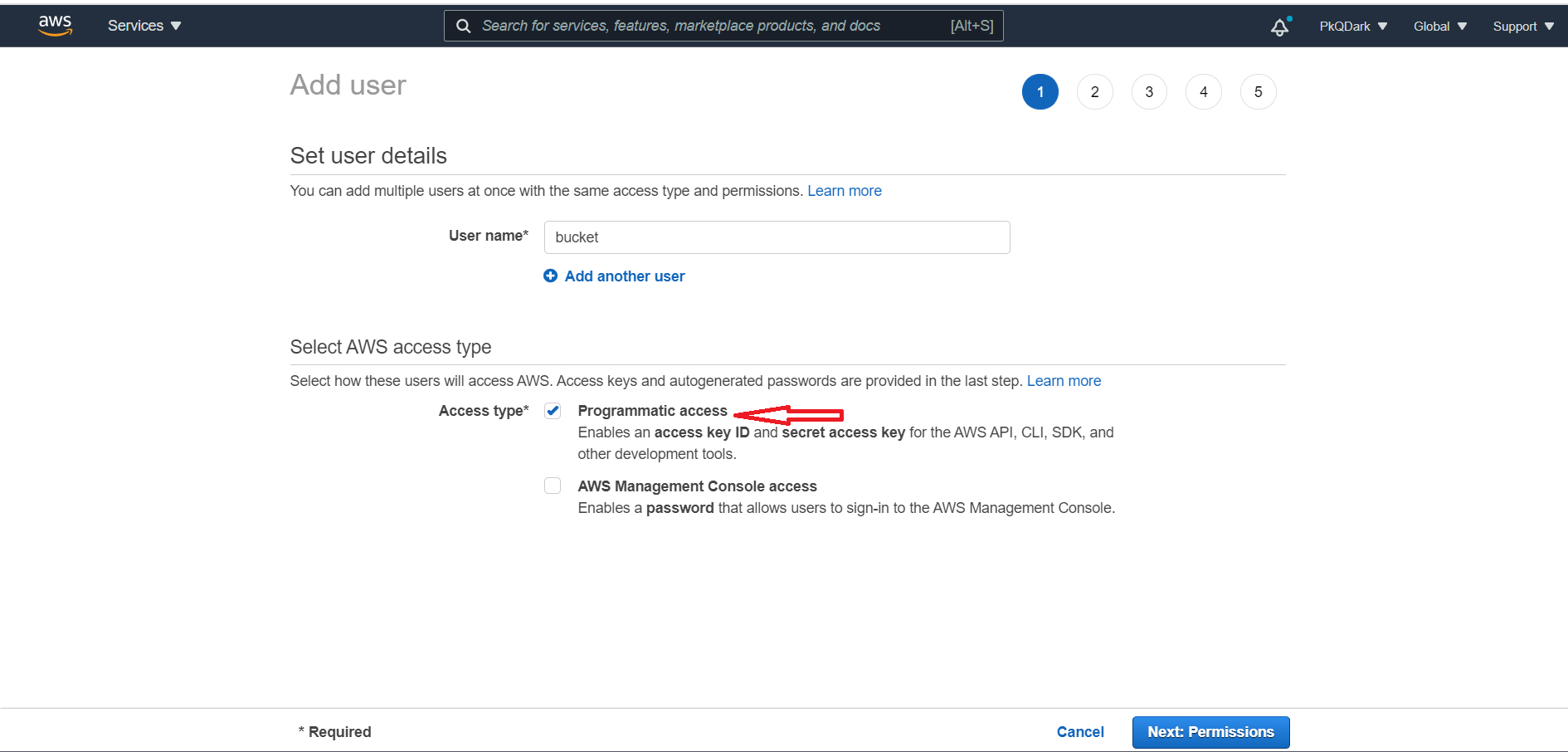
Выбираем Programmatic access наш пользователь не будет заходить в настройки, только генерировать токен.
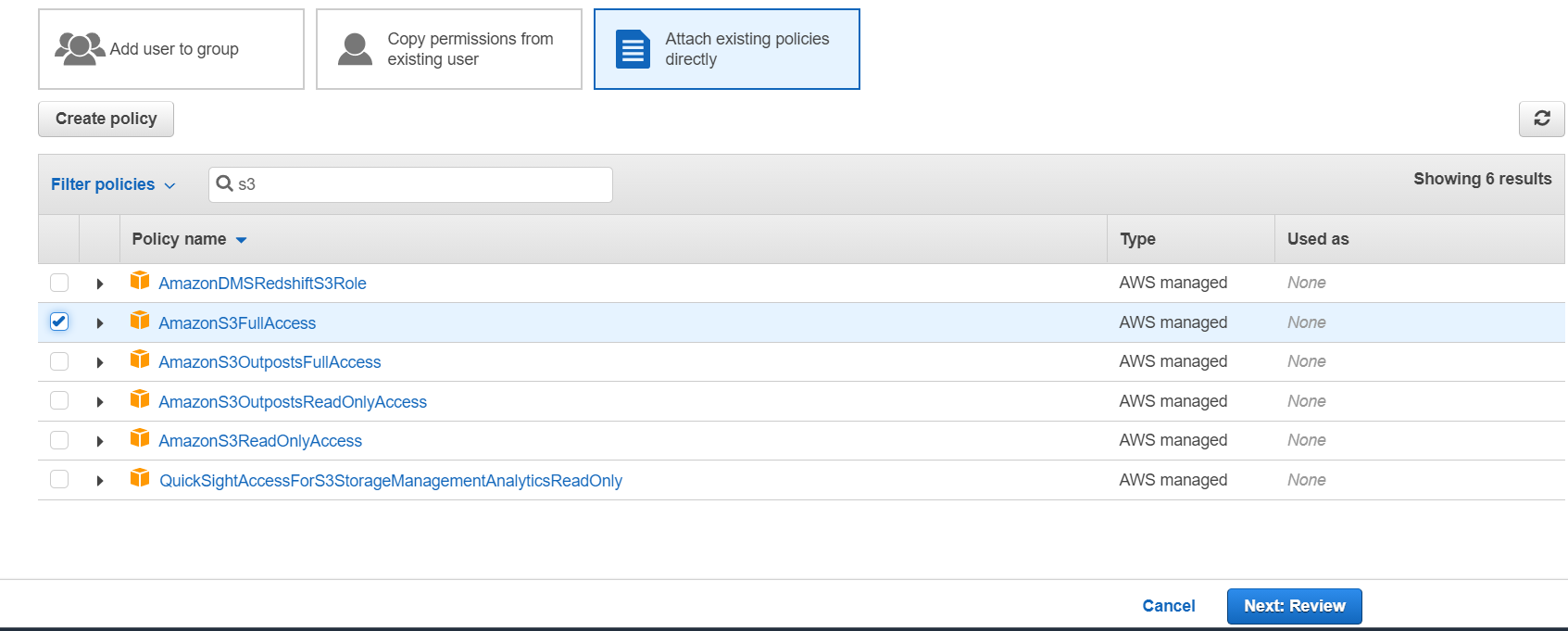
Добавляем пользователю полные права на S3 Bucket.
Обязательно сохраняем ключи от пользователя.
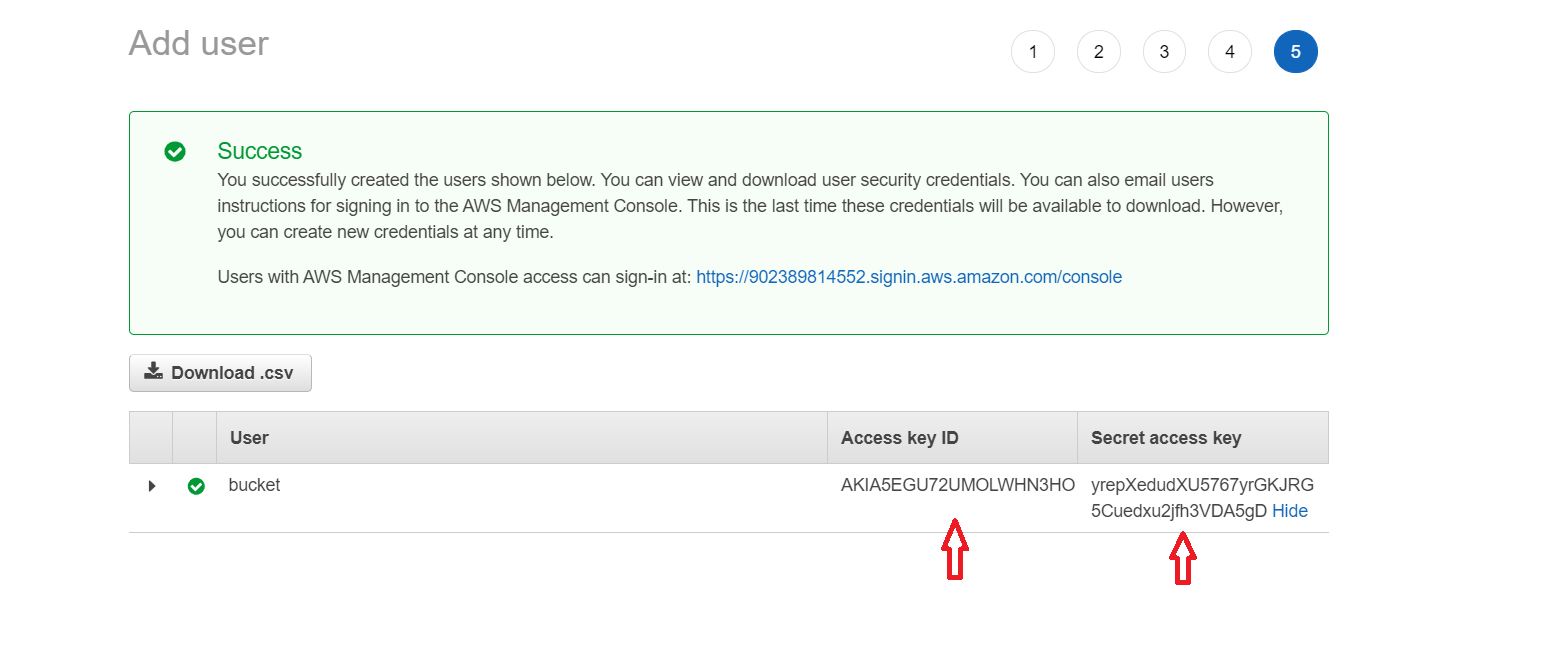
Никогда, нет, НИКОГДА не выкладываем эти ключи на git (в settings.py или где-либо еще). Amazon мониторит
абсолютно весь интернет. :) И если ваши ключи окажутся в открытом репозитории, пользователь будет мгновенно
заблокирован, а владельцу аккаунта напишут об этом письмо и позвонят, чтобы предупредить.
Создадим новый S3 Bucket в регионе us-east-1, с ним самая простая настройка.
С полностью закрытым доступом к файлам.
Для использования S3 в нашем проекте нужно доставить Python модули:
pip install django-storages boto3
Если вы будете использовать S3 и локально, то можно установить пакеты и локально, но чаще всего для локальных тестов внешние сервисы не используются.
Для использования нужно добавить storages в INSTALLED_APPS:
INSTALLED_APPS = [
...,
'storages',
]после чего достаточно добавить настройки:
# Optional
AWS_S3_OBJECT_PARAMETERS = {
'Expires': 'Thu, 31 Dec 2099 20:00:00 GMT',
'CacheControl': 'max-age=94608000',
}
# Required
AWS_STORAGE_BUCKET_NAME = 'BUCKET_NAME'
AWS_S3_REGION_NAME = 'REGION_NAME' # e.g. us-east-2
AWS_ACCESS_KEY_ID = 'xxxxxxxxxxxxxxxxxxxx'
AWS_SECRET_ACCESS_KEY = 'yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy'
# НЕ ВПИСЫВАЙТЕ САМИ КЛЮЧИ, ТОЛЬКО os.environ.get('SOME_KEY')
# Tell the staticfiles app to use S3Boto3 storage when writing the collected static files (when
# you run `collectstatic`).
STATICFILES_STORAGE = 'storages.backends.s3boto3.S3Boto3Storage'Этого достаточно, чтобы команда collectstatic собирала всю статику в S3 Bucket от Amazon, а template tag static
генерировал URL с параметрами безопасности, получить такую статику просто так нельзя.
AWS_S3_OBJECT_PARAMETERS - необязательный параметр, чтобы указать настройки объектов, параметров довольно много.
Но при такой настройке вся статика будет просто сложена в S3 Bucket, как на свалке, куда же мы поместим медиа?
Чтобы сложить статику и медиа в один S3 Bucket, нужно создать новые классы для storages, где указать папки для хранения разных типов данных.
Создадим файл custom_storages.py на одном уровне с settings.py.
# custom_storages.py
from django.conf import settings
from storages.backends.s3boto3 import S3Boto3Storage
class StaticStorage(S3Boto3Storage):
location = settings.STATICFILES_LOCATION
class MediaStorage(S3Boto3Storage):
location = settings.MEDIAFILES_LOCATIONА в settings.py укажем:
# settings.py
STATICFILES_LOCATION = 'static'
STATICFILES_STORAGE = 'custom_storages.StaticStorage'
MEDIAFILES_LOCATION = 'media'
DEFAULT_FILE_STORAGE = 'custom_storages.MediaStorage'Этого полностью достаточно, чтобы команда collectstatic собрала всё статику в папку static на S3 Bucket, а любые
загруженные пользователями файлы - в папку media.
Добавляем все необходимые переменные окружения, запускаем collectstatic, убеждаемся, что всё собрано правильно, и
статика работает, так же можем попробовать загрузить что-либо и убедиться, что медиа грузится правильно (если такой
функционал заложен в проект).
При таком подходе Nginx не обрабатывает статику и медиа, а значит, что эти строки можно не вносить (или удалить из конфига).
Route 53 - это сервис, где вы можете зарегистрировать домен, и привязать его к вашему IP адресу, чтобы использовать URL, а не IP.
Я заранее купил домен a-level-test.com :) Поэтому, если я открою вкладку Hosted zones, то увижу:
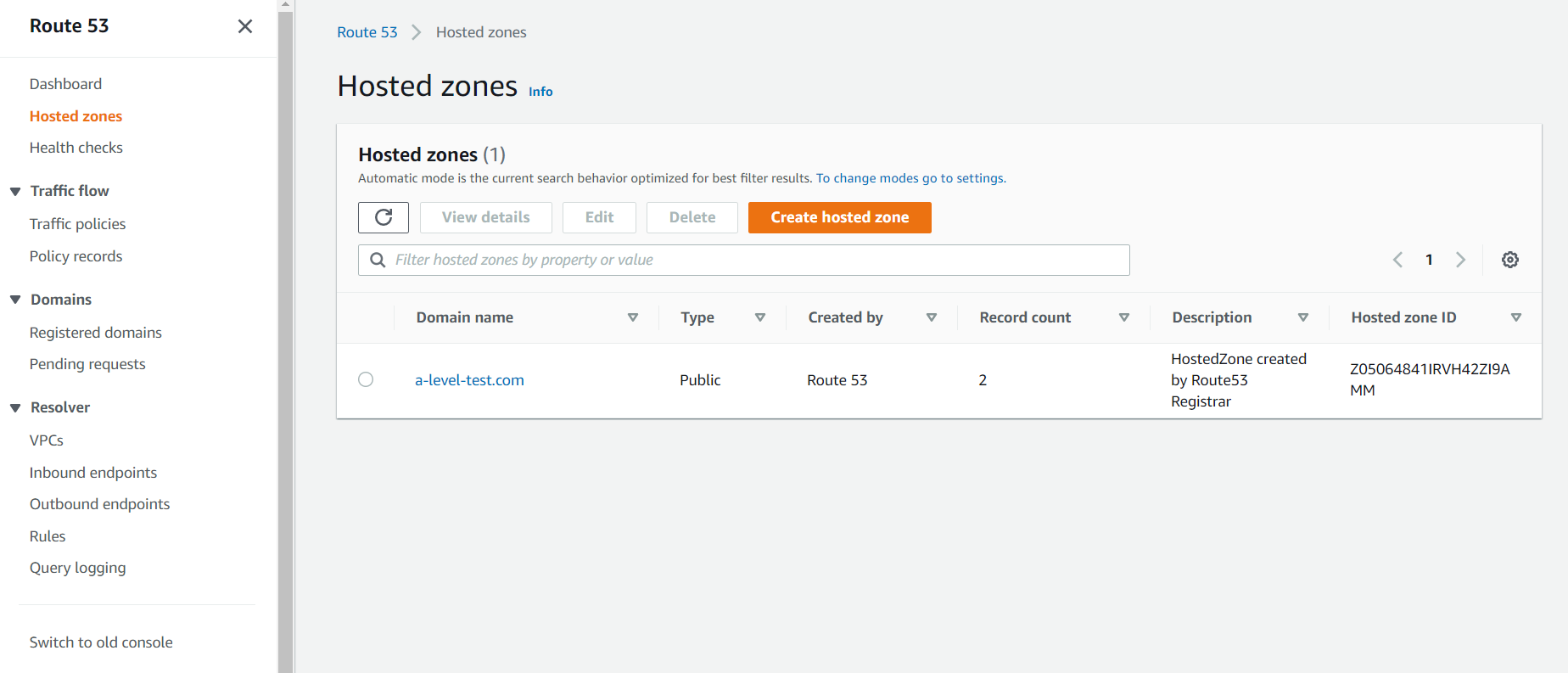
Создам новую запись в hosted zone:
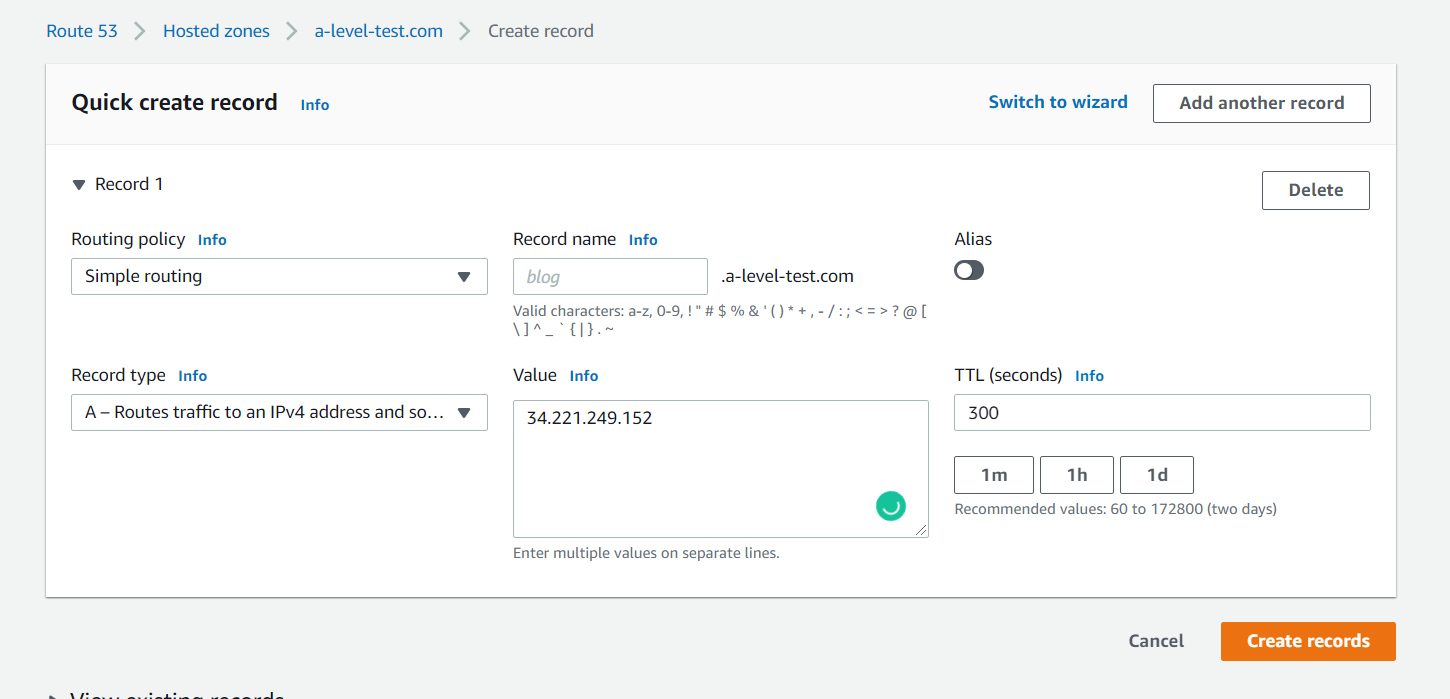
В поле value я указал IP, который выдал мне Amazon к моему инстансу.
В settings.py в ALLOWED_HOSTS нужно добавить новый URL.
...
DEBUG = False
ALLOWED_HOSTS = ['a-level-test.com']
...Пулим новый код, перезапускаем gunicorn:
sudo systemctl restart gunicorn
После этого мне нужно обновить Nginx и поменять там server_name;
server {
listen 80;
server_name a-level-test.com;
location / {
include proxy_params;
proxy_pass http://unix:/home/ubuntu/deployment/r/gunicorn.sock;
}
}
Перезапускаем Nginx:
sudo service nginx restart
Открываем URL, убеждаемся, что всё работает и статика не потерялась.
Наше соединение работает, но при этом абсолютно не защищено. Почему мы не сделали его безопасным раньше? Всё просто,
сертификат для включения https привязывается к URL, а не к IP адресу.
Сделать это можно очень просто и в практически автоматическом режиме.
Для начала необходимо доставить на сервер некоторые модули:
sudo apt install certbot python3-certbot-nginx
И выполнить команду:
sudo certbot --nginx -d a-level-test.com
После параметра -d указывается server_name из Nginx;
Certbot спросит у вас почту, если это первый запуск, попросит принять условия и указать, редиректить небезопасное соединение в безопасное или нет, всё зависит от ваших условий.
Он автоматически заменит и перезапустит конфигурацию Nginx:
server {
server_name a-level-test.com;
location / {
include proxy_params;
proxy_pass http://unix:/home/ubuntu/deployment/r/gunicorn.sock;
}
listen 443 ssl; # managed by Certbot
ssl_certificate /etc/letsencrypt/live/a-level-test.com/fullchain.pem; # managed by Certbot
ssl_certificate_key /etc/letsencrypt/live/a-level-test.com/privkey.pem; # managed by Certbot
include /etc/letsencrypt/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam /etc/letsencrypt/ssl-dhparams.pem; # managed by Certbot
}
server {
if ($host = a-level-test.com) {
return 301 https://$host$request_uri;
} # managed by Certbot
listen 80;
server_name a-level-test.com;
return 404; # managed by Certbot
}
Не забываем открыть порт номер 443 для нашего инстанса.
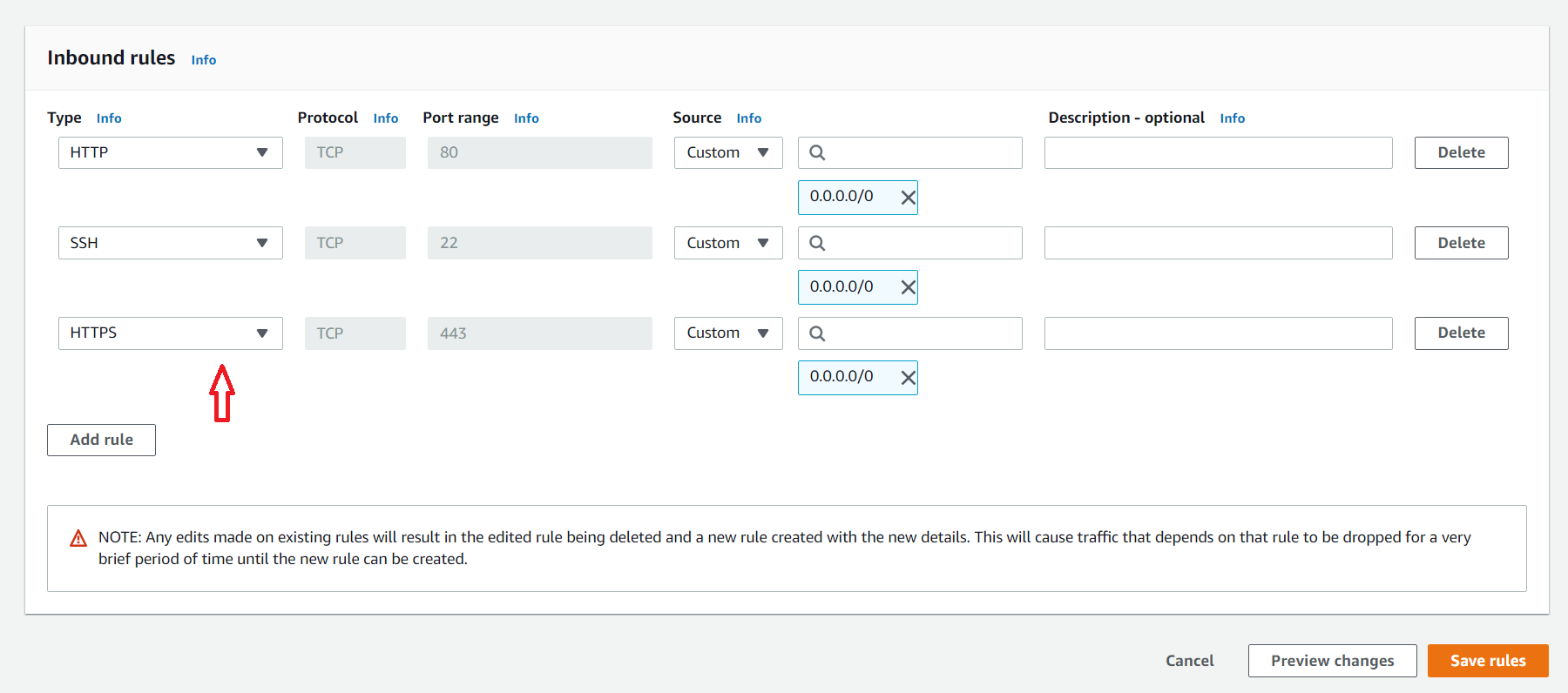
Всё, пробуем открыть сайт и видим, что он теперь безопасен.
Сертификаты Let’s Encrypt действительны только в течение 90 дней. Это сделано для стимулирования пользователей к
автоматизации процесса обновления сертификатов. Установленный нами пакет certbot выполняет это автоматически, добавляя
таймер systemd, который будет запускаться два раза в день и автоматически продлевать все сертификаты, истекающие
менее, чем через 30 дней.
Чтобы протестировать процесс обновления, можно сделать запуск «вхолостую» с помощью certbot:
sudo certbot renew --dry-run
Если ошибок нет, все нормально. Certbot будет продлевать ваши сертификаты, когда это потребуется, и перезагружать Nginx для активации изменений. Если процесс автоматического обновления когда-нибудь не выполнится, то Let’s Encrypt отправит сообщение на указанный вами адрес электронной почты с предупреждением о том, что срок действия сертификата подходит к концу.