
Мы уже знаем про то, как хранить данные и как связать таблицы между собой. Давайте научимся извлекать, модифицировать и удалять данные при помощи кода.
Допустим, что ваша модель выглядит так:
from django.db import models
from django.contrib.auth.models import User
from django.utils import timezone
from django.utils.translation import gettext as _
GENRE_CHOICES = (
(1, _("Not selected")),
(2, _("Comedy")),
(3, _("Action")),
(4, _("Beauty")),
(5, _("Other"))
)
class Author(models.Model):
pseudonym = models.CharField(max_length=120,
blank=True,
null=True)
name = models.CharField(max_length=120)
def __str__(self):
return self.name
class Article(models.Model):
author = models.ForeignKey(Author,
on_delete=models.CASCADE,
null=True,
related_name='articles')
text = models.TextField(max_length=10000,
null=True)
created_at = models.DateTimeField(default=timezone.now)
updated_at = models.DateTimeField(default=timezone.now)
genre = models.IntegerField(choices=GENRE_CHOICES,
default=1)
def __str__(self):
return f"Author - {self.author.name}, genre - {self.genre}, id - {self.id}"
class Comment(models.Model):
text = models.CharField(max_length=1000)
article = models.ForeignKey(Article,
on_delete=models.DO_NOTHING)
comment = models.ForeignKey('myapp.Comment',
null=True,
blank=True,
on_delete=models.DO_NOTHING,
related_name='comments')
user = models.ForeignKey(User,
on_delete=models.DO_NOTHING)
def __str__(self):
return f"{self.text} by {self.user.username}"
class Like(models.Model):
user = models.ForeignKey(User,
on_delete=models.DO_NOTHING)
article = models.ForeignKey(Article,
on_delete=models.DO_NOTHING)
def __str__(self):
return f"By user {self.user.username} to article {self.article.id}"Рассмотрим некоторые новые возможности
from django.contrib.auth.models import UserЭто модель встроенного в Django юзера, её мы рассмотрим немного позже.
from django.utils.translation import gettext as _Стандартная функция перевода языка для Django. Допустим, что ваш сайт имеет функцию переключения языка, при которой текст может отображаться на русском, украинском и английском. Именно эта функция поможет нам в будущем указать значения для всех трех языков. Подробнейшая информация по переводам Тут
Мы будем рассматривать это на отдельной лекции
GENRE_CHOICES = (
(1, _("Not selected")),
(2, _("Comedy")),
(3, _("Action")),
(4, _("Beauty")),
(5, _("Other"))
)Переменная, состоящая из кортежа кортежей (могла быть любая коллекция коллекций), которая нужна для использования choices значений, используется для хранения выбора чего-либо (в нашем случае жанра). То есть в базе будет храниться только число, а пользователю будет выводиться уже текст.
Используем это вот тут:
genre = models.IntegerField(choices=GENRE_CHOICES, default=1)Рассмотрим вот эту строку
return f"Author - {self.author.name}, genre - {self.genre}, id - {self.id}"self.author.name - в базе по значению поля ForeignKey хранится id, но в коде мы можем получить доступ к значениям связанной модели, конкретно в этой ситуации мы берем значение поля name из связанной модели author.
Рассмотрим вот эту строку:
comment = models.ForeignKey('myapp.Comment',
null=True,
blank=True,
on_delete=models.DO_NOTHING,
related_name='comments')Модель можно передать не только как класс, но и по имени модели указав приложение appname.Modelname (да, мне было лень
переименовывать приложение из myapp во что-то читаемое).
Это пример самоссылочной связи, помните еще из занятий по
SQL?
При такой записи мы создаём связь один ко многим к самому себе, указав при этом black=True, null=True. Можно создать коммент без указания родительского комментария, а если создать комментарий со ссылкой на другой, это будет комментарий к комментарию, причем это можно сделать любой вложенности.
Кроме описания модели можно было бы использовать текст self. Это работает, когда нужно сделать ссылку именно на самого
себя
related_name - в этой записи нужен для того, чтобы получить выборку всех вложенных объектов. Мы рассмотрим их немного
дальше.
Для доступа или модификации любых данных, у каждой модели есть атрибут objects, который позволяет производить
манипуляции с данными. Он называется менеджер, и при желании его можно переопределить.
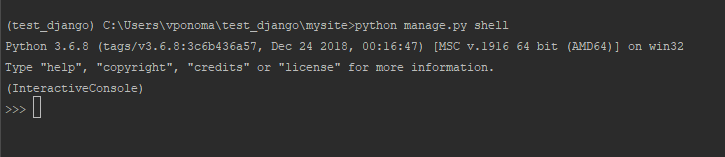
Для интерактивного использования кода используется команда
python manage.py shell
Эта команда открывает нам консоль с уже импортированными стандартными, но не самописными модулями Django
Предварительно я создал несколько объектов через админку.
Для доступа к моделям их нужно импортировать, я импортирую модель Comment.
Рассмотрим весь CRUD и дополнительные особенности. Очень подробная информация по всем возможным операциям тут
Функции для получения объектов в Django могут возвращать два типа данных, объект модели или queryset
Объект - это единичный объект, queryset - это список объектов со своими встроенными методами.
Для получения всех данных используется метод all(), который возвращает queryset со всеми существующими объектами этой
модели.

Для получения отфильтрованных данных мы используем метод filter()
Если указать filter() без параметров, то он сделает то же самое, что и all().
Какие у фильтра могу быть параметры? Да практически любые, мы можем указать любые поля для фильтрации. Например, фильтр по полю текст:
Comment.objects.filter(text='Hey everyone')Фильтр по вложенным объектам выполняется через двойное подчеркивание.
Фильтр по жанру статьи комментария:
Comment.objects.filter(article__genre=3)По псевдониму автора:
Comment.objects.filter(article__author__pseudonym='The king')По псевдониму автора и жанру (через запятую можно указать логическое И):
Comment.objects.filter(article__author__pseudonym='The king', article__genre=3)Кроме того, у каждого поля существуют встроенные системы лукапов. Синтаксис лукапов аналогичен синтаксису доступа к
вложенным
объектам field__lookuptype=value
Стандартные лукапы:
lte - меньше или равно
gte - больше или равно
lt - меньше
gt - больше
startswith - начинается с
istartswith - начинается с, без учёта регистра
endswith - заканчивается на
iendswith - заканчивается на, без учёта регистра
range - находится в диапазоне
week_day - день недели (для дат)
year - год (для дат)
isnull - является null
contains - частично содержит с учетом регистра ("Всем привет, я - Влад" содержит слово "Влад", но не содержит "влад")
icontains - то же самое, но без учета регистра, теперь найдется и второй вариант.
exact - совпадает (необязательный лукап, делает то же, что и знак равно)
iexact - совпадает без учета регистра (по запросу "привет" найдет и "Привет", и "прИвЕт")
in - содержится в каком-то списке
Их намного больше, читать ТУТ
Примеры:
Псевдоним содержит слово 'king' без учета регистра:
Comment.objects.filter(article__author__pseudonym__icontains='king')Комменты к статье, созданной не позднее чем вчера:
Comment.objects.filter(article__created_at__gte=date.today() - timedelta(days=1))Комменты к статьям с жанрами, у которых id = 2 и id = 3:
Comment.objects.filter(article__genre__in=[2, 3])Функция обратная функции filter вытащит всё, что не попадает выборку.
Например, все комментарии к статьям, у которых жанр id != 2 и id != 3:
Comment.objects.exclude(article__genre__in=[2, 3])filter и exclude можно совмещать. К любому queryset можно применить filter или exclude еще раз. Например, все
комменты
к статьям, созданным не позже чем вчера, с жанрами не 2 и не 3
Comment.objects.filter(article__created_at__gte=date.today() - timedelta(days=1)).exclude(article__genre__in=[2, 3])Все эти функции возвращают специальный объект называемый queryset. Он является коллекцией записей базы (которые называются в этой терминологии instance), к любому кверисету можно применить любой метод менеджера модели (objects). Например, к только что отфильтрованному кверисету можно применить фильтр еще раз и т. д.
По умолчанию все модели сортируются по полю id, если явно не указанно иное. Однако часто нужно отсортировать данные
специальным
образом. Для этого используется метод order_by(). При сортировке можно указывать вложенные объекты и знак -, чтобы
указать сортировку в обратном порядке.
Comment.objects.filter(article__created_at__gte=date.today() - timedelta(days=1)).order_by('-article__created_at').all()Метод distinct() используется для исключения дублирующихся записей из результата запроса. Он полезен, когда вам нужно
получить уникальные записи по одному или нескольким полям.
Предположим, у нас есть модель Book с полями title, author, и published_date.
from myapp.models import Book
# Получение уникальных авторов
unique_authors = Book.objects.distinct('author')В этом примере запрос вернет уникальные записи на основе поля author. Если не указать поле, то метод distinct()
уберет дубликаты всех записей.
Метод values() используется для создания набора запросов, который возвращает словари, где ключами являются имена
полей, а значениями — их значения. Это удобно, когда вам нужно получить определенные поля из базы данных, а не все поля
модели.
# Получение всех названий книг
book_titles = Book.objects.values('title')Этот запрос вернет список словарей, где каждый словарь будет содержать ключ title и соответствующее ему значение.
Метод union() позволяет объединять два или более QuerySets. Результат будет содержать уникальные записи, которые
присутствуют в любом из QuerySets.
from myapp.models import Book
# QuerySet с книгами, опубликованными до 2000 года
old_books = Book.objects.filter(published_date__lt="2000-01-01")
# QuerySet с книгами, опубликованными после 2020 года
new_books = Book.objects.filter(published_date__gt="2020-01-01")
# Объединение двух QuerySets
books_union = old_books.union(new_books)В результате books_union будут содержаться книги, опубликованные либо до 2000 года, либо после 2020 года.
Метод intersection() используется для получения пересечения двух или более QuerySets. В результате запроса будут
только те записи, которые присутствуют во всех QuerySets.
from myapp.models import Book
# QuerySet с книгами определенного автора
author_books = Book.objects.filter(author="J.K. Rowling")
# QuerySet с книгами, опубликованными до 2000 года
old_books = Book.objects.filter(published_date__lt="2000-01-01")
# Пересечение двух QuerySets
books_intersection = author_books.intersection(old_books)В этом примере books_intersection вернет только те книги Дж. К. Роулинг, которые были опубликованы до 2000 года.
Метод difference() используется для получения разности между двумя QuerySets, то есть он возвращает записи, которые
присутствуют в одном QuerySet, но отсутствуют в другом.
from myapp.models import Book
# QuerySet со всеми книгами
all_books = Book.objects.all()
# QuerySet с книгами, опубликованными до 2000 года
old_books = Book.objects.filter(published_date__lt="2000-01-01")
# Разность между всеми книгами и старыми книгами
books_difference = all_books.difference(old_books)В этом примере books_difference будет содержать все книги, которые были опубликованы после 2000 года.
Это далеко не всё, что можно сделать с queryset.
Все методы кверисетов читаем Тут
Помимо прочего во все фильтры(и не только) можно вставлять целые объекты, например:
art = Article.objects.get(id=2)
comments = Comment.object.filter(article=art)В отличие от filter и exclude метод get получает сразу объект. Этот метод работает только в том случае, когда
можно
определить объект однозначно и он существует.
Можно применять те же условия, что и для filter и exclude
Например, получения объекта по id
Comment.objects.get(id=3)Если объект не найден или найдено больше одного объекта по заданным параметрам, вы получите исключение, которое желательно всегда обрабатывать. Исключения уже находятся в самой модели.
try:
Comment.objects.get(article__genre__in=[2, 3])
except Comment.DoesNotExist:
return "Can't find object"
except Comment.MultipleObjectsReturned:
return "More than one object"К кверисету можно применять методы first и last, чтобы получить первый или последний элемент кверисета
Например, получить первый коммент, написанный за вчера:
Comment.objects.filter(article__created_at__gte=date.today() - timedelta(days=1)).first()Информация по всем остальным методам Тут
Атрибут related_name, который указывается для полей связи, является обратной связью и менеджером для объектов,
например, в нашей модели у поля author модели Article есть related_name=articles:
a = Author.objects.first()
articles = a.articles.all() # Тут будут все статьи конкретного автора в виде кверисета, т.к. all() возвращает кверисетМожно ли получить объекты обратной связи без указания related_name? Можно. Связь появляется автоматически даже без
указания этого атрибута.
Обратный менеджер формируется из названия модели и конструкции _set. Допустим, у поля article модели Comment не
указано поле related_name:
a = Article.objects.first()
a.comment_set.all() # такой же менеджер, как в прошлом примере, вернёт кверисет комментариев, относящихся к этой статье.Для создания новых объектов используется два возможных варианта: метод create() или метод save()
Создадим двух новых авторов при помощи разных методов:
Author.objects.create(name='New author by create', pseudonym="Awesome author")
a = Author(name="Another new author", pseudonym="Gomer")
a.save()В чём же разница? В том, что в первом случае при выполнении этой строки запрос в базу будет отправлен сразу, во втором -
только при вызове метода save()
Метод save() также является и методом для обновления значения поля, если применяется для уже существующего объекта. Мы
рассмотрим его подробнее немного дальше.
Для обновления значений полей используется метод update()
Применяется только к кверисетам, к объекту применить нельзя
Например, обновим текст в комментарии с id = 3:
Comment.objects.filter(id=3).update(text='updated text')
ИЛИ
c = Comment.objects.get(id=3)
c.text = 'updated text'
c.save()Как можно догадаться, выполняется методом delete().
Удалить все комменты от пользователя с id = 2:
Comment.objects.filter(user__id=2).delete()get_or_create() - это метод, который попытается создать новый объект. Если он не сможет найти нужный в базе, он
возвращает сам объект и булево значение, которое обозначает, что объект был создан или получен.
update_or_create() - обновит, если объект существует, создаст, если не существует.
bulk_create() - массовое создание; необходимо для того, чтобы избежать большого количества обращений в базу.
bulk_update() - массовое обновление (отличие от обычного в том, что при обычном на каждый объект создается запрос,
в этом случае запрос делается массово)
Подробно почитать про них Тут
SQLзапрос выполняется именно при вызове методаsave, методаdeleteили изменении M2M о чем ниже.
Метод save() применяется при любых изменениях или создании данных, но очень часто нужно, чтобы при сохранении данных
выполнялись еще какие-либо действия, переписывание данных или запись логов и т. д. Для этого используется переписывание
метода save(). По сути является способом написать аналог триггера в базе данных.
Метод save() вызывают явно или неявно во время вызова методов создания или обновления, но без него запись в базу не
будет произведена.
Допустим, мы хотим делать время создания статьи на один день раньше, чем фактическая. Перепишем метод save() для
статьи:
class MyAwesomModel(models.Model):
name = models.CharField(max_lenght=100)
created_at = models.DateField()
def save(self, **kwargs):
self.created_at = timezone.now() - timedelta(days=1)
super().save(**kwargs)Переопределяем значение и вызываем оригинальный save(), вуаля.
Чтобы переопределить логику при создании, но не трогать при изменении, или наоборот, используется особенность
данных. У уже созданного объекта id существует, у нового - нет. Так что фактически наш код сейчас обновляет это поле
всегда, и когда надо, и когда не надо. Допишем его.
class MyAwesomModel(models.Model):
name = models.CharField(max_lenght=100)
created_at = models.DateField()
def save(self, **kwargs):
if not self.id:
self.created_at = timezone.now() - timedelta(days=1)
super().save(**kwargs)Теперь поле будет переписываться только в момент создания, но не будет трогаться при обновлении.
Метод delete(), при удалении объекта save() не вызывается, а вызывается delete(). По аналогии мы можем его
переписать, например, для отправки имейла перед удалением.
class MyAwesomModel(models.Model):
name = models.CharField(max_lenght=100)
created_at = models.DateField()
def delete(self, **kwargs):
send_email(id=self.id)
super().delete(**kwargs)Допустим у нас есть вот такие модели:
from django.db import models
class Publication(models.Model):
title = models.CharField(max_length=30)
class Meta:
ordering = ["title"]
def __str__(self):
return self.title
class Article(models.Model):
headline = models.CharField(max_length=100)
publications = models.ManyToManyField(Publication)
class Meta:
ordering = ["headline"]
def __str__(self):
return self.headlineДля работы с М2М связями используются методы менеджера add и remove
Создадим несколько объектов:
p1 = Publication(title="The Python Journal")
p1.save()
p2 = Publication(title="Science News")
p2.save()
p3 = Publication(title="Science Weekly")
p3.save()Мы могли сделать то же самое через
Publication.objects.create(), но тут нам будет важно отследитьSQLзапросы
a1 = Article(headline="Django lets you build web apps easily")Если не сохранить статью и попытаться вызвать изменения в M2M, то вы увидите вот такую ошибку:
a1.publications.add(p1)
# Traceback (most recent call last):
# ValueError: "<Article: Django lets you build web apps easily>" needs to have a value for field "id" before this many-to-many relationship can be used.Потому что объект a1 пока что сущетствует только на уровне питона, но его нет на уровне базы данных.
Давайте сохраним объект и попробуем еще раз изменить M2M
a1.save()
a1.publications.add(p1) # Тут вызовется еще один `SQL` запросИ еще пример:
a2 = Article(headline="NASA uses Python")
a2.save()
a2.publications.add(p1, p2)
a2.publications.add(p3)Как видите можно добавлять более чем один объект за раз
А что если добавить объект не того типа который ожидается?
a2.publications.add(a1)
# TypeError: 'Publication' instance expectedБудет ошибка о неправильном типе!
Можно создать и сразу добавить объект вот так
new_publication = a2.publications.create(title="Highlights for Children")Метод создаст объект, добавит его к М2М и вернет в новую переменную
В нашем случае publications является менеджером, а значит, что к нему применимы все действия как и к обычному
objects
a1.publications.all()
# <QuerySet [<Publication: The Python Journal>]>
a2.publications.all()
# <QuerySet [<Publication: Highlights for Children>, <Publication: Science News>, <Publication: Science Weekly>, <Publication: The Python Journal>]>Естественно
allв этом случае будет возвращать только те объекты которые связаны с запрашиваемым
И так же как и при связи через FK, мы можем использовать related_name для получения объектов в другом порядке (из
той модели, где менеджер не прописан)
p2.article_set.all()
# <QuerySet [<Article: NASA uses Python>]>
p1.article_set.all()
# <QuerySet [<Article: Django lets you build web apps easily>, <Article: NASA uses Python>]>
Publication.objects.get(id=4).article_set.all()
# <QuerySet [<Article: NASA uses Python>]>
related_nameне прописан явно, поэтому мы используем стандартно сгенерированный
Так как ссылка является менеджером, это значит, что к ней применим весь спектр процессов доступных менеджеру. Например
filter, distinct или count
Article.objects.filter(publications__id=1)
# <QuerySet [<Article: Django lets you build web apps easily>, <Article: NASA uses Python>]>
Article.objects.filter(publications__pk=1)
# <QuerySet [<Article: Django lets you build web apps easily>, <Article: NASA uses Python>]>
Article.objects.filter(publications=1)
# <QuerySet [<Article: Django lets you build web apps easily>, <Article: NASA uses Python>]>
Article.objects.filter(publications=p1)
# <QuerySet [<Article: Django lets you build web apps easily>, <Article: NASA uses Python>]>
Article.objects.filter(publications__title__startswith="Science")
# <QuerySet [<Article: NASA uses Python>, <Article: NASA uses Python>]>
Article.objects.filter(publications__title__startswith="Science").distinct()
# <QuerySet [<Article: NASA uses Python>]>
Article.objects.filter(publications__title__startswith="Science").count()
# 2
Article.objects.filter(publications__title__startswith="Science").distinct().count()
# 1
Article.objects.filter(publications__in=[1, 2]).distinct()
# <QuerySet [<Article: Django lets you build web apps easily>, <Article: NASA uses Python>]>
Article.objects.filter(publications__in=[p1, p2]).distinct()
# <QuerySet [<Article: Django lets you build web apps easily>, <Article: NASA uses Python>]>Любые действия с менеджером доступны как напрямую, так и через
related_name
a4.publications.remove(p2)
p2.article_set.all()
# <QuerySet [<Article: Oxygen-free diet works wonders>]>
a4.publications.all()
# <QuerySet []>И с другой стороны
p2.article_set.remove(a5)
p2.article_set.all()
# <QuerySet []>
a5.publications.all()
# <QuerySet []>Можно назначить список который будет отображать связь:
a4.publications.all()
# <QuerySet [<Publication: Science News>]>
a4.publications.set([p3])
a4.publications.all()
# <QuerySet [<Publication: Science Weekly>]>Или очистить всю связь:
p2.article_set.clear()
p2.article_set.all()
# <QuerySet []>Назаначение как и очистка так же работает с обоих концов, как и любое другое действие с менеджерами.
Документация по этому разделу
На самом деле, мы не ограничены стандартными конструкциями. Мы можем применять предвычисления на уровне базы, добавлять логические конструкции и т. д., давайте рассмотрим подробнее.
Как вы могли заметить в случае фильтрации, мы можем выбрать объекты через логическое И при помощи запятой.
Comment.objects.filter(article__author__pseudonym='The king', article__genre=3)В этом случае у нас есть конструкция типа "выбрать объекты, у которых псевдоним автора статьи The king И жанр статьи
цифра 3"
Но что же нам делать, если нам нужно использовать логическое ИЛИ?
В этом нам поможет использование Q объекта. На самом деле, каждое из этих условий мы могли завернуть в такой объект:
from django.db.models import Q
q1 = Q(article__author__pseudonym='The king')
q2 = Q(article__genre=3)Теперь мы можем явно использовать логические И и ИЛИ.
Comment.objects.filter(q1 & q2) # И
Comment.objects.filter(q1 | q2) # ИЛИАгрегация в Django - это предвычисления.
Допустим, что у нас есть модели:
from django.db import models
class Author(models.Model):
name = models.CharField(max_length=100)
age = models.IntegerField()
class Publisher(models.Model):
name = models.CharField(max_length=300)
class Book(models.Model):
name = models.CharField(max_length=300)
pages = models.IntegerField()
price = models.DecimalField(max_digits=10,
decimal_places=2)
rating = models.FloatField()
authors = models.ManyToManyField(Author)
publisher = models.ForeignKey(Publisher,
on_delete=models.CASCADE)
pubdate = models.DateField()
class Store(models.Model):
name = models.CharField(max_length=300)
books = models.ManyToManyField(Book)Мы можем совершить предвычисления каких-либо средних, минимальных, максимальных значений, вычислить сумму и т. д.
from django.db.models import Avg
Book.objects.all().aggregate(Avg('price'))
# {'price__avg': 34.35}На самом деле, all() не несёт пользы в этом примере:
Book.objects.aggregate(Avg('price'))
# {'price__avg': 34.35}Значение можно именовать:
Book.objects.aggregate(average_price=Avg('price'))
# {'average_price': 34.35}Можно вносить больше одной агрегации за раз:
from django.db.models import Avg, Max, Min
Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
# {'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}Если нам нужно, чтобы подсчитанное значение было у каждого объекта модели, мы используем метод annotate()
# Build an annotated queryset
from django.db.models import Count
q = Book.objects.annotate(Count('authors'))
# Interrogate the first object in the queryset
q[0]
# "<Book: The Definitive Guide to Django>"
q[0].authors__count
# 2
# Interrogate the second object in the queryset
q[1]
# "<Book: Practical Django Projects>"
q[1].authors__count
# 1Их тоже может быть больше одного:
book = Book.objects.first()
book.authors.count()
# 2
book.store_set.count()
# 3
q = Book.objects.annotate(Count('authors'), Count('store'))
q[0].authors__count
# 6
q[0].store__count
# 6Все эти вещи можно комбинировать:
highly_rated = Count('book', filter=Q(book__rating__gte=7))
Author.objects.annotate(num_books=Count('book'), highly_rated_books=highly_rated)c сортировкой (ordering):
Book.objects.annotate(num_authors=Count('authors')).order_by('num_authors')В Django ORM (Object-Relational Mapping) для работы с базой данных часто возникает необходимость обновления полей
модели, сравнения значений полей между собой или выполнения арифметических операций на уровне базы данных. Для этих
целей в Django используется класс F.
F объекты представляют собой способ обращения к полям модели без необходимости загружать их в память приложения.
Вместо этого операции с F объектами выполняются непосредственно на уровне базы данных, что может значительно повысить
производительность при выполнении запросов.
Рассмотрим простой пример: допустим, у нас есть модель Product, которая имеет поле price. Предположим, что нам нужно
увеличить цену каждого товара на 10%.
from django.db.models import F
Product.objects.update(price=F('price') * 1.10)Этот запрос обновит поле price для всех записей, увеличив его значение на 10%. При этом Django выполнит операцию
умножения на уровне базы данных, что исключит необходимость загружать все объекты в память.
Предположим, у нас есть модель Order с полями quantity и shipped_quantity. Нам нужно найти все заказы, для которых
количество отгруженного товара меньше заказанного.
from myapp.models import Order
from django.db.models import F
orders = Order.objects.filter(shipped_quantity__lt=F('quantity'))Этот запрос вернет все заказы, где количество отгруженного товара (shipped_quantity) меньше заказанного (quantity).
Рассмотрим пример, когда у нас есть модель Employee с полем bonus. Мы хотим увеличить бонус на 500 для всех
сотрудников, у которых текущий бонус менее 1000.
from django.db.models import F, Q
Employee.objects.filter(bonus__lt=1000).update(bonus=F('bonus') + 500)Этот запрос обновит поле bonus, прибавив к текущему значению 500 для всех сотрудников, у которых бонус меньше 1000.
Предположим, у нас есть модель Sale с полями quantity и unit_price, и мы хотим узнать общую стоимость каждого
товара, умножив количество на цену за единицу.
from django.db.models import F, Sum
total_sales = Sale.objects.annotate(total_price=F('quantity') * F('unit_price'))Этот запрос добавит к каждому объекту Sale дополнительное поле total_price, содержащее общую стоимость товара.
В некоторых случаях удобно использовать F объекты в аннотациях для создания вычисляемых полей. Например, предположим,
что у нас есть модель Invoice с полями subtotal и discount. Мы хотим добавить аннотацию с окончательной суммой
счета, учитывая скидку.
from django.db.models import F, ExpressionWrapper, FloatField
invoices = Invoice.objects.annotate(
total=ExpressionWrapper(F('subtotal') - F('discount'), output_field=FloatField())
)Здесь мы используем ExpressionWrapper, чтобы указать Django тип возвращаемого значения, поскольку операции с F
объектами могут привести к неоднозначности типов данных.
Когда вы работаете с базой данных в Django, важно учитывать, сколько запросов вы выполняете и насколько эффективны эти
запросы. Один из частых антипаттернов – это проблема "N+1 запросов", когда для получения данных выполняется множество
запросов, что замедляет работу приложения. Django предоставляет два мощных инструмента для оптимизации
запросов: select_related и prefetch_related.
Предположим, у нас есть две модели Author и Book, связанные отношением "один ко многим":
class Author(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=100)
author = models.ForeignKey(Author, on_delete=models.CASCADE)Теперь, если вы хотите вывести список книг и их авторов:
books = Book.objects.all()
for book in books:
print(book.title, book.author.name)Это пример проблемы "N+1 запросов". Сначала выполняется один запрос для получения всех книг, а затем для каждой книги выполняется отдельный запрос для получения автора, что приводит к множеству запросов (N+1).
Метод select_related позволяет выполнять запросы с объединением (JOIN) таблиц, что значительно уменьшает количество
запросов к базе данных. Он используется для отношений "ForeignKey" и "OneToOne".
books = Book.objects.select_related('author').all()
for book in books:
print(book.title, book.author.name)В данном случае будет выполнен один SQL-запрос, использующий JOIN для получения данных о книгах и их авторах одновременно.
Когда вы используете select_related, Django выполняет SQL-запрос с использованием INNER JOIN или LEFT OUTER JOIN,
чтобы получить связанные объекты в рамках одного запроса. Это очень эффективно для отношений "один ко многим" и "один к
одному".
Метод prefetch_related используется для оптимизации запросов, когда у вас есть отношение "многие ко многим" или "один
ко многим", и вы хотите избежать проблемы "N+1 запросов". В отличие от select_related, он выполняет отдельные запросы,
но затем обрабатывает их в Python, чтобы уменьшить общее количество запросов.
Предположим, у вас есть модели:
class Publisher(models.Model):
name = models.CharField(max_length=100)
class Book(models.Model):
title = models.CharField(max_length=100)
publisher = models.ForeignKey(Publisher, on_delete=models.CASCADE)
authors = models.ManyToManyField(Author)Теперь, если вы хотите получить все книги и авторов для каждого из них:
books = Book.objects.prefetch_related('authors').all()
for book in books:
print(book.title)
for author in book.authors.all():
print(author.name)Здесь prefetch_related выполнит два отдельных запроса: один для получения всех книг, а второй для получения всех
авторов, которые связаны с этими книгами. Django затем связывает авторов с книгами в Python, избегая проблемы "N+1
запросов".
prefetch_related делает два (или более) отдельных запроса и затем соединяет результаты этих запросов в Python. Это
очень полезно для отношений "многие ко многим" или если вы хотите выполнить сложные фильтрации на связанном наборе
данных.
select_relatedиспользуется для выполнения SQL JOIN и эффективен для отношений "ForeignKey" и "OneToOne". Все происходит на уровне базы данных.prefetch_relatedиспользуется для отношений "многие ко многим" и "один ко многим". Он выполняет несколько запросов и объединяет результаты на уровне Python.
Представьте, что у нас есть следующие модели:
class Store(models.Model):
name = models.CharField(max_length=100)
class Product(models.Model):
name = models.CharField(max_length=100)
store = models.ForeignKey(Store, on_delete=models.CASCADE)
suppliers = models.ManyToManyField(Supplier)
class Supplier(models.Model):
name = models.CharField(max_length=100)Теперь, если нам нужно получить все продукты с их магазинами и поставщиками:
products = Product.objects.select_related('store').prefetch_related('suppliers').all()
for product in products:
print(product.name, product.store.name)
for supplier in product.suppliers.all():
print(supplier.name)Этот пример сочетает оба подхода. Мы используем select_related для получения связанных магазинов с использованием JOIN
и prefetch_related для получения поставщиков, выполняя несколько запросов.
В Django ORM управление транзакциями можно осуществлять с помощью встроенных инструментов, таких
как atomic, transaction.on_commit, а также с помощью ручного управления транзакциями через API транзакций.
Рассмотрим примеры для каждого из этих подходов.
atomic — это контекстный менеджер или декоратор, который гарантирует, что все операции внутри блока будут выполнены в
одной транзакции. Если внутри блока возникает исключение, транзакция откатывается.
from django.db import transaction
from myapp.models import MyModel
def create_records():
try:
with transaction.atomic():
obj1 = MyModel.objects.create(name="Object 1")
obj2 = MyModel.objects.create(name="Object 2")
# Если здесь возникнет исключение, то обе записи не будут добавлены
except Exception as e:
print(f"Transaction failed: {e}")from django.db import transaction
from myapp.models import MyModel
@transaction.atomic
def create_records():
obj1 = MyModel.objects.create(name="Object 1")
obj2 = MyModel.objects.create(name="Object 2")
# Если здесь возникнет исключение, то обе записи не будут добавленыon_commit позволяет зарегистрировать функцию, которая будет выполнена только в случае успешного завершения транзакции.
from django.db import transaction
from myapp.models import MyModel
def notify_user():
print("Transaction committed successfully!")
def create_record():
with transaction.atomic():
obj = MyModel.objects.create(name="Object 1")
transaction.on_commit(notify_user)
# notify_user будет вызвана только если транзакция завершится успешноМожно управлять транзакциями вручную, открывая и закрывая транзакции с помощью методов transaction.commit()
и transaction.rollback().
from django.db import transaction
from myapp.models import MyModel
def create_records():
try:
transaction.set_autocommit(False) # Отключаем автокоммит
obj1 = MyModel.objects.create(name="Object 1")
obj2 = MyModel.objects.create(name="Object 2")
transaction.commit() # Явно фиксируем транзакцию
except Exception as e:
transaction.rollback() # Откатываем транзакцию в случае ошибки
print(f"Transaction failed: {e}")
finally:
transaction.set_autocommit(True) # Включаем автокоммит обратноИспользование транзакций в Django ORM позволяет вам контролировать целостность данных, обеспечивая атомарность операций. Вы можете использовать контекстный менеджер или декоратор
atomicдля автоматического управления транзакциями, либо вручную управлять транзакциями для более точного контроля над процессом.