|
| 1 | +--- |
| 2 | +title: '王树森推荐系统学习笔记_排序' |
| 3 | +description: "" |
| 4 | +date: "2025-09-27" |
| 5 | +tags: |
| 6 | + - tag-one |
| 7 | +--- |
| 8 | + |
| 9 | +# 王树森推荐系统学习笔记_排序 |
| 10 | + |
| 11 | +## 排序 |
| 12 | + |
| 13 | +### 多目标排序模型 |
| 14 | + |
| 15 | +**用户一笔记的交互** |
| 16 | + |
| 17 | +- 对于每篇笔记,系统记录: |
| 18 | + - **曝光次数**(*number of impressions*) |
| 19 | + - **点击次数**(*number of clicks*) |
| 20 | + - **点赞次数**(*number of likes*) |
| 21 | + - **收藏次数**(*number of collects*) |
| 22 | + - **转发次数**(*number of shares*) |
| 23 | + |
| 24 | +- **点击率** = 点击次数/曝光次数 |
| 25 | +- **点赞率** = 点赞次数/点击次数 |
| 26 | +- **收藏率** = 收藏次数/点击次数 |
| 27 | +- **转发率** = 转发次数/点击次数 |
| 28 | + |
| 29 | +**排序的依据** |
| 30 | + |
| 31 | +- 排序模型预估点击率、点赞率、收藏率、转发率等多种分数。 |
| 32 | +- 融合这些预估分数。(*比如加权和。*) |
| 33 | +- 根据融合的分数做排序、截断。 |
| 34 | + |
| 35 | +#### 多目标模型 |
| 36 | + |
| 37 | +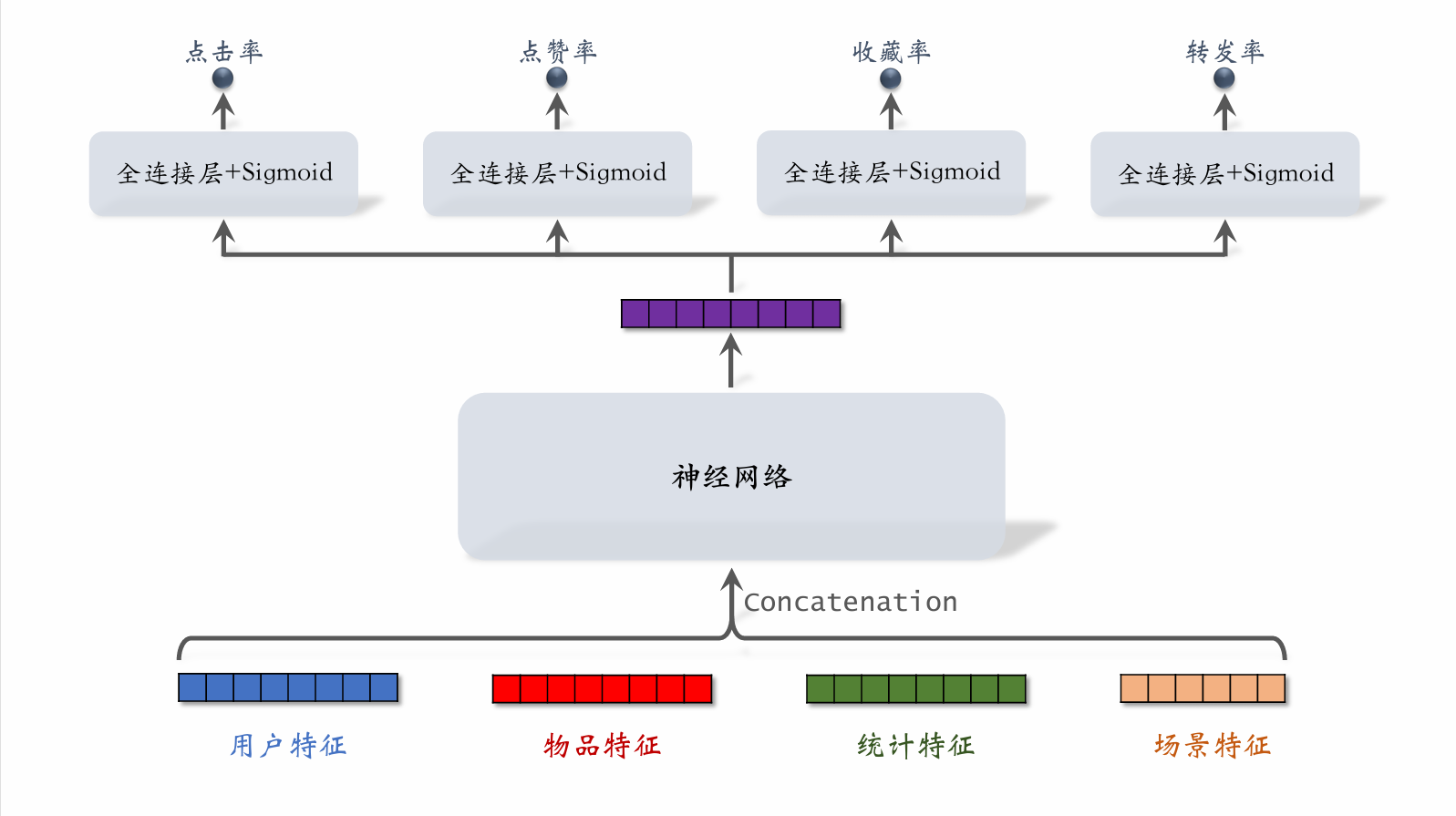 |
| 38 | + |
| 39 | +- 用户特征:如用户ID,用户画像 |
| 40 | +- 物品特征:如物品ID,物品画像,作者信息 |
| 41 | +- 统计特征:如用户在过去一段时间内曝光了多少篇笔记,点击了多少篇笔记,点赞了多少篇笔记。物品在过去一段时间内获得了多少曝光机会,被点击了多少次,点赞了多少次 |
| 42 | +- 场景特征:如当前的时间,用户所在的地点 |
| 43 | + |
| 44 | + |
| 45 | + |
| 46 | +训练: |
| 47 | + |
| 48 | +- 对于点击率来说,模型实际上就是根据点击率来判断一个物品是否为被点击物品。这是一个二元分类问题,因此用交叉熵损失函数。 |
| 49 | + |
| 50 | +- 总的损失函数: $ \sum_{i=1}^{4} \alpha_i \cdot \text{CrossEntropy}(y_i, p_i) $ 。 |
| 51 | +- 对损失函数求梯度,做梯度下降更新参数。 |
| 52 | + |
| 53 | +**训练** |
| 54 | + |
| 55 | +- 困难:类别不平衡。 |
| 56 | + - 每 100 次曝光,约有 10 次点击,90 次无点击。 |
| 57 | + - 每 100 次点击,约有 10 次收藏,90 次无收藏。 |
| 58 | + - 负样本与正样本数量差距悬殊,多出的负样本意义不大,浪费计算资源。 |
| 59 | + |
| 60 | +- 解决方案:负样本降采样(*down-sampling*) |
| 61 | + - 保留一小部分负样本。 |
| 62 | + - 让正负样本数量平衡,节约计算。 |
| 63 | + |
| 64 | +#### 预估值校准 |
| 65 | + |
| 66 | +- 正样本、负样本数量为 $n_+$ 和 $n_-$。 |
| 67 | +- 对负样本做降采样,抛弃一部分负样本。 |
| 68 | +- 使用 $ \alpha \cdot n_- $ 个负样本,$ \alpha \in (0,1) $ 是采样率。 |
| 69 | +- 由于负样本变少,**预估点击率** 大于 **真实点击率**。而且 $\alpha$ 越小,负样本越少,模型对点击率高估就越严重。 |
| 70 | + |
| 71 | + |
| 72 | + |
| 73 | +- **真实点击率**: |
| 74 | + |
| 75 | +$$ |
| 76 | +p_{\text{true}} = \frac{n_+}{n_+ + n_-} \quad (\text{期望}) |
| 77 | +$$ |
| 78 | + |
| 79 | +- **预估点击率**: |
| 80 | + |
| 81 | +$$ |
| 82 | +p_{\text{pred}} = \frac{n_+}{n_+ + \alpha \cdot n_-} \quad (\text{期望}) |
| 83 | +$$ |
| 84 | + |
| 85 | +- 由上面两个等式可得校准公式 : |
| 86 | + |
| 87 | +$$ |
| 88 | +p_{\text{true}} = \frac{\alpha \cdot p_{\text{pred}}}{(1 - p_{\text{pred}}) + \alpha \cdot p_{\text{pred}}}。 |
| 89 | +$$ |
| 90 | + |
| 91 | +### Multi-gate Mixture-of-Experts (MMoE) |
| 92 | + |
| 93 | + |
| 94 | +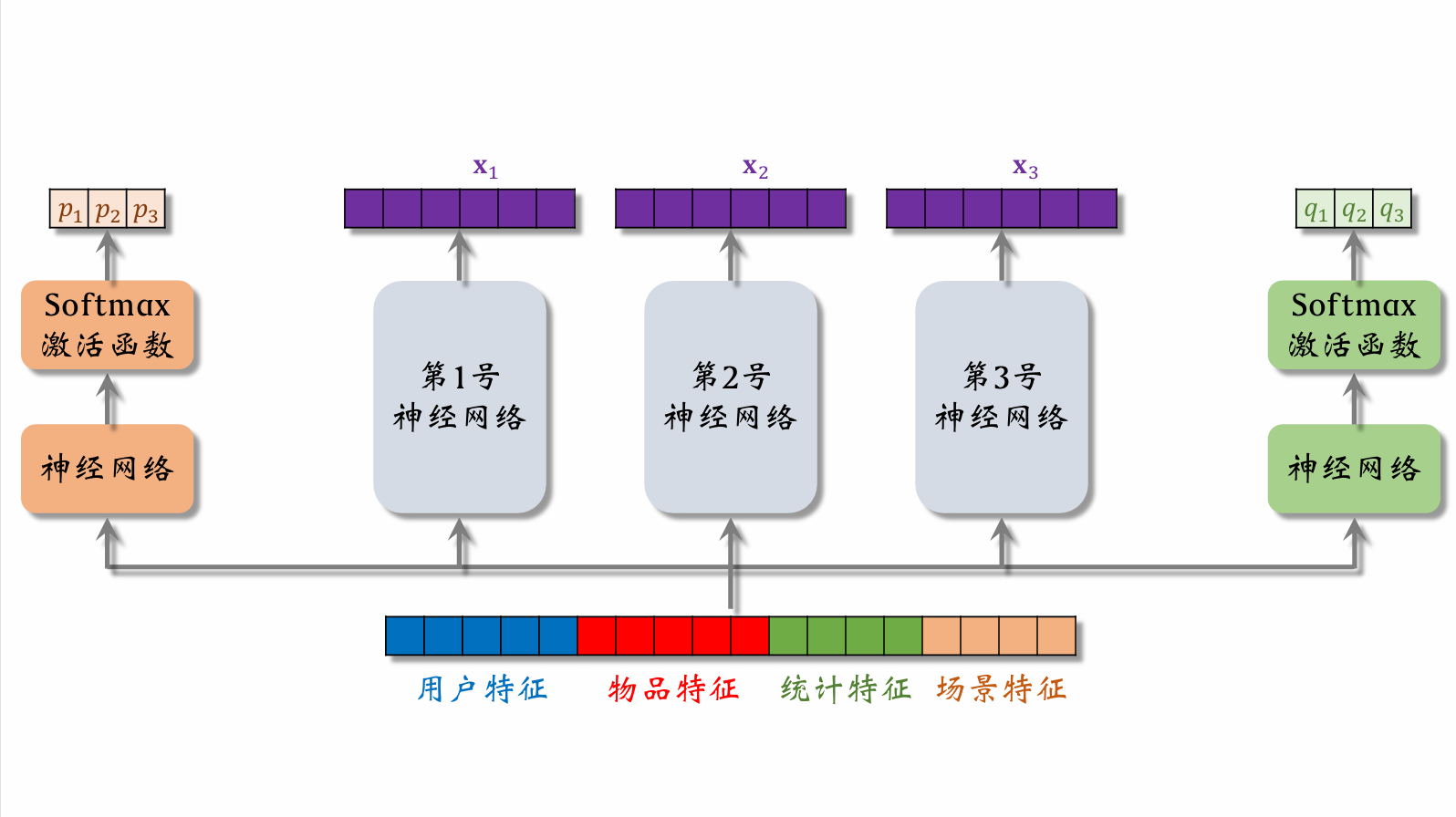 |
| 95 | + |
| 96 | +1号,2号,3号神经网络分别是专家神经网络。 |
| 97 | + |
| 98 | +将用户特征,物品特征,统计特征和行为特征输入到左侧的神经网络中,再经过 softmax 激活函数得到一个权重向量,这种神经网络也叫做门控神经网络。向量中的三个值 $p_1,p_2,p_3$ 分别代表着对 $x_1,x_2,x_3$ 的权重值。右侧神经网络同理。 |
| 99 | + |
| 100 | +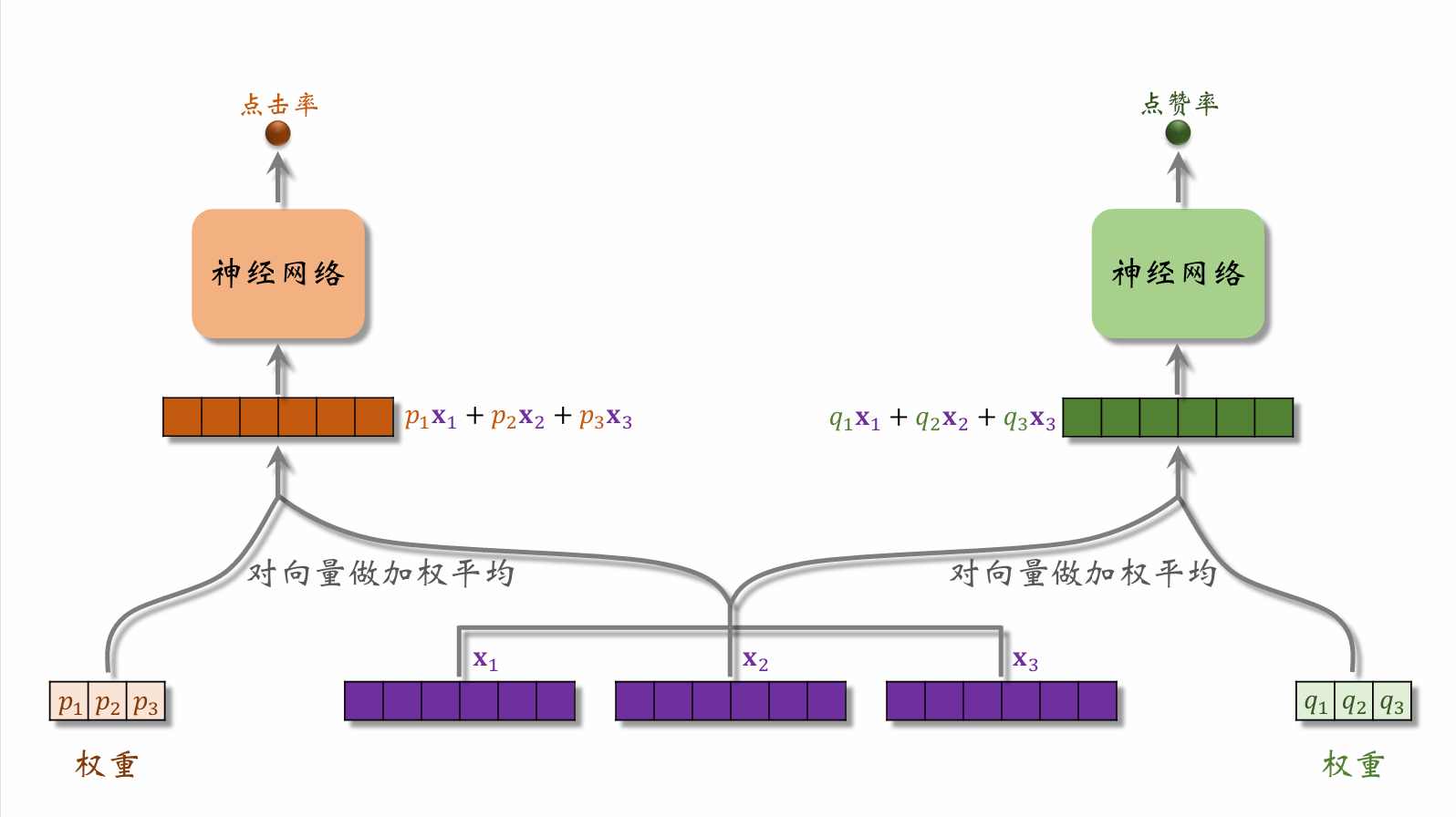 |
| 101 | + |
| 102 | +将左侧门控神经网络输出的权重向量与专家神经网络生成的特征向量结合,输入到左侧的任务神经网络中,预测点击率。右侧同理。 |
| 103 | + |
| 104 | +#### 极化现象(Polarization) |
| 105 | + |
| 106 | +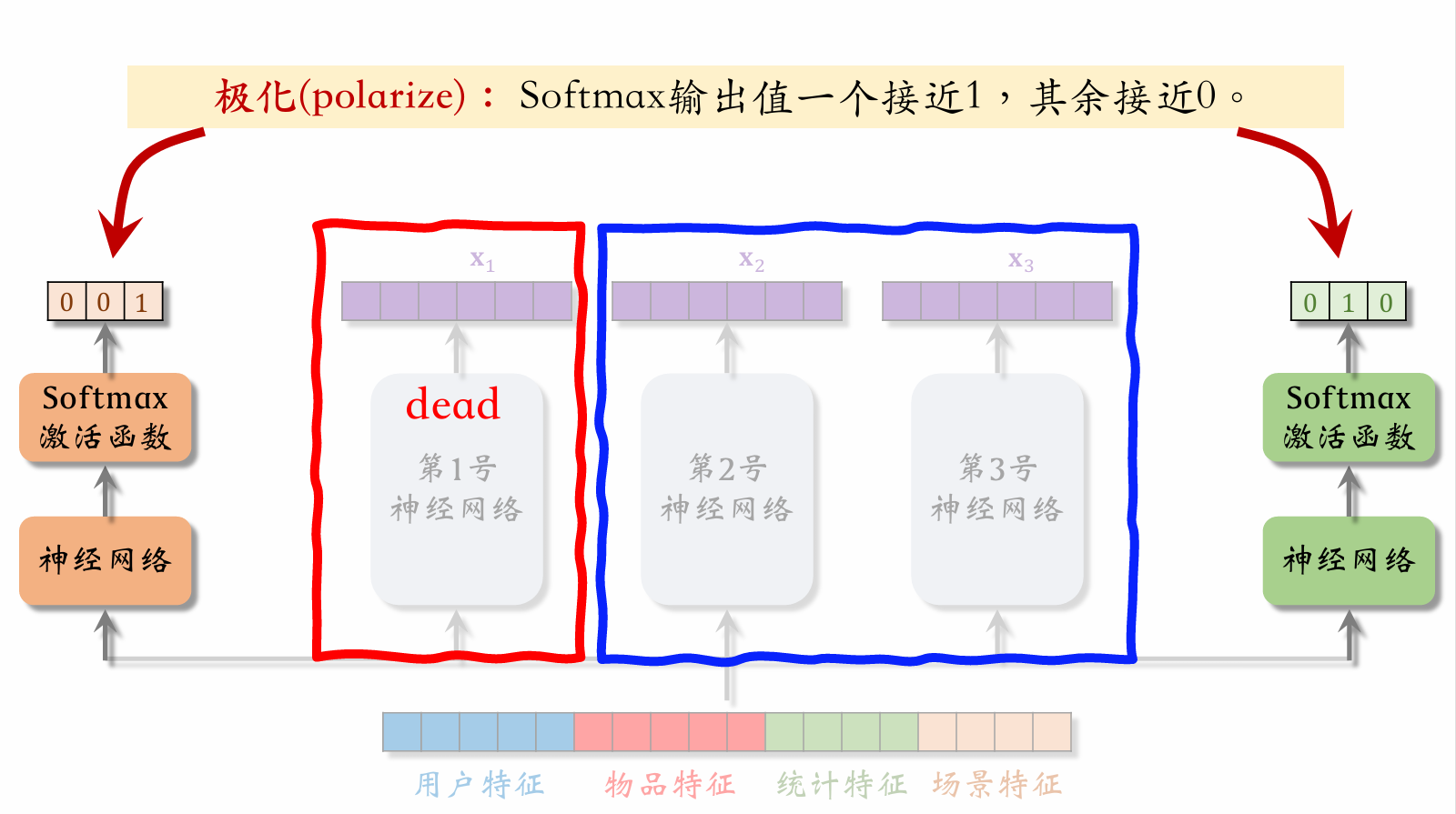 |
| 107 | + |
| 108 | +当左侧门控神经网络输出向量中 3 号专家神经网络的权重接近 1,其余接近 0。右侧门控神经网络输出向量中 2 号专家神经网络的权重接近 1,其余接近 0。这样加权过后就会导致 1 号神经网络的输出向量没有参与模型工作。应该尽量避免这种情况。 |
| 109 | + |
| 110 | +#### 解决极化问题 |
| 111 | + |
| 112 | +- 如果有 $n$ 个“专家”,那么每个 softmax 的输入和输出都是 $n$ 维向量。 |
| 113 | + |
| 114 | +- **在训练时,对 softmax 的输出使用 dropout**。 |
| 115 | + - Softmax 输出的 $n$ 个数值被 mask 的概率都是 10%。 |
| 116 | + - 每个“专家”被随机丢弃的概率都是 10%。 |
| 117 | + |
| 118 | +### 预估分数的融合 |
| 119 | + |
| 120 | +**简单的加权和** |
| 121 | + |
| 122 | +$$ |
| 123 | +p_{\text{click}} + w_1 \cdot p_{\text{like}} + w_2 \cdot p_{\text{collect}} + \cdots |
| 124 | +$$ |
| 125 | + |
| 126 | +**点击率乘以其他项的加权和** |
| 127 | + |
| 128 | +$$ |
| 129 | +p_{\text{click}} \cdot \left( 1 + w_1 \cdot p_{\text{like}} + w_2 \cdot p_{\text{collect}} + \cdots \right) |
| 130 | +$$ |
| 131 | + |
| 132 | +- $p_{\text{click}}= \frac{\text{点击}}{\text{曝光}}$ |
| 133 | +- $p_{\text{like}}\ = \frac{\text{点赞}}{\text{点击}}$ |
| 134 | + |
| 135 | +**国内某短视频 APP 的融合分公式** |
| 136 | + |
| 137 | +- 根据预估时长 $p_{\text{time}}$,对 $n$ 篇候选视频做排序。 |
| 138 | +- 如果某视频排名第 $r_{\text{time}}$ ,则它得分 $ \frac{1}{r_{\text{time}}^{\alpha} + \beta} $。 |
| 139 | +- 对点击、点赞、转发、评论等预估分数做类似处理。 |
| 140 | +- 最终融合分数:( $\alpha_{1,2,3\dots}$ 为超参数) |
| 141 | + |
| 142 | +$$ |
| 143 | +\frac{w_1}{r_{\text{time}}^{\alpha_1} + \beta_1} + \frac{w_2}{r_{\text{click}}^{\alpha_2} + \beta_2} + \frac{w_3}{r_{\text{like}}^{\alpha_3} + \beta_3} + \cdots |
| 144 | +$$ |
| 145 | + |
| 146 | +**某电商的融合分公式** |
| 147 | + |
| 148 | +- 电商的转化流程: |
| 149 | + |
| 150 | + $$\text{曝光} \rightarrow \text{点击} \rightarrow \text{加购物车} \rightarrow \text{付款}$$ |
| 151 | + |
| 152 | +- 模型预估:$ p_{\text{click}} $、$ p_{\text{cart}} $、$ p_{\text{pay}} $。 |
| 153 | + |
| 154 | +- 最终融合分数:( $\alpha_{1,2,3,4\dots}$ 为超参数) |
| 155 | + |
| 156 | +$$ |
| 157 | +p_{\text{click}}^{\alpha_1} \times p_{\text{cart}}^{\alpha_2} \times p_{\text{pay}}^{\alpha_3} \times \text{price}^{\alpha_4} |
| 158 | +$$ |
| 159 | + |
| 160 | +### 视频播放建模 |
| 161 | + |
| 162 | +#### 视频播放时长 |
| 163 | + |
| 164 | +**图文 vs 视频** |
| 165 | + |
| 166 | +- 图文笔记排序的主要依据: |
| 167 | + |
| 168 | + *点击、点赞、收藏、转发、评论⋯⋯* |
| 169 | + |
| 170 | +- 视频排序的依据还有播放时长和完播。 |
| 171 | + |
| 172 | +- 直接用回归拟合播放时长效果不好。建议用 YouTube 的时长建模 。 |
| 173 | + |
| 174 | +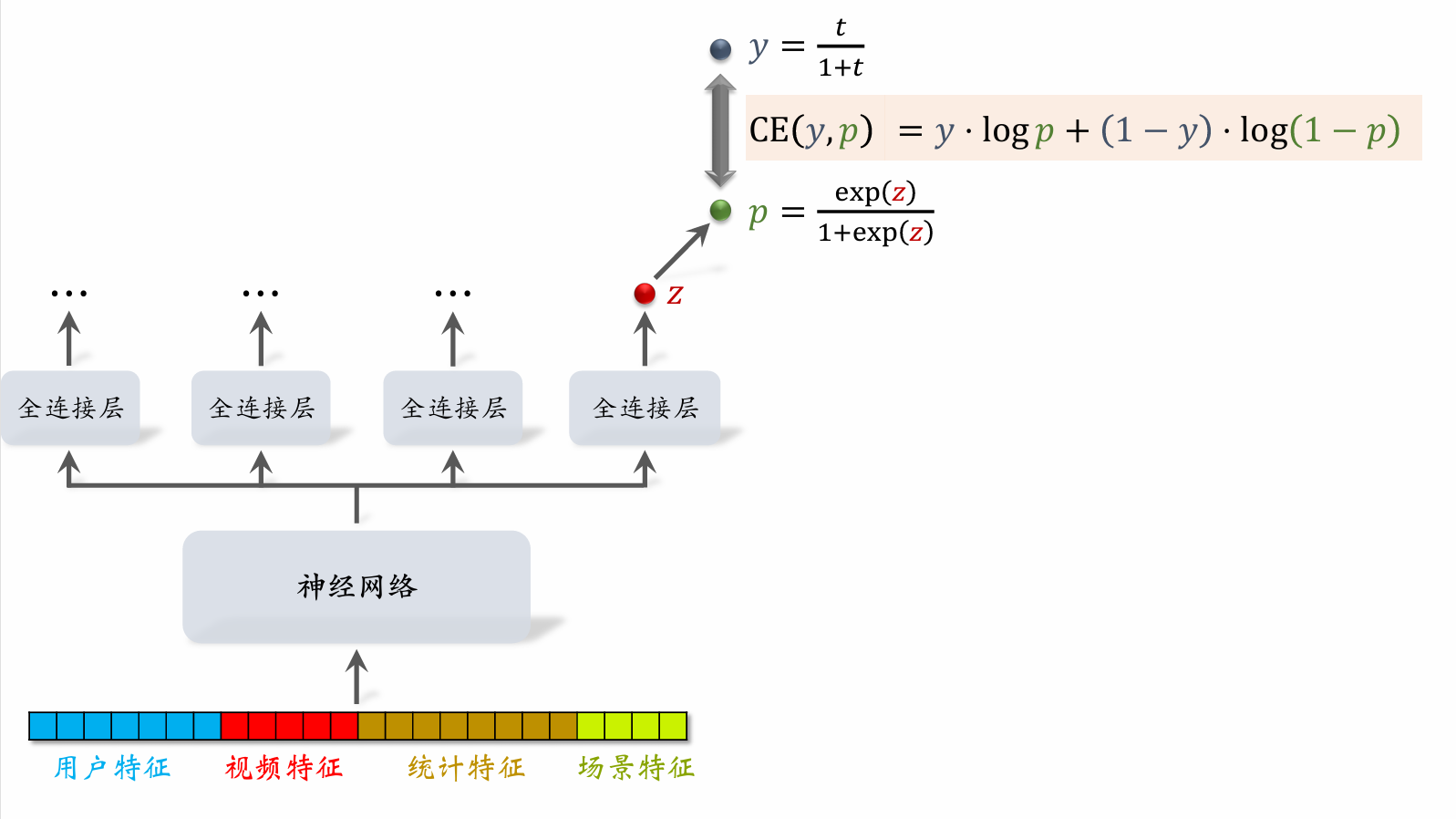 |
| 175 | + |
| 176 | +如果 $p = y$,那么 $\exp(z) = t$。 |
| 177 | + |
| 178 | +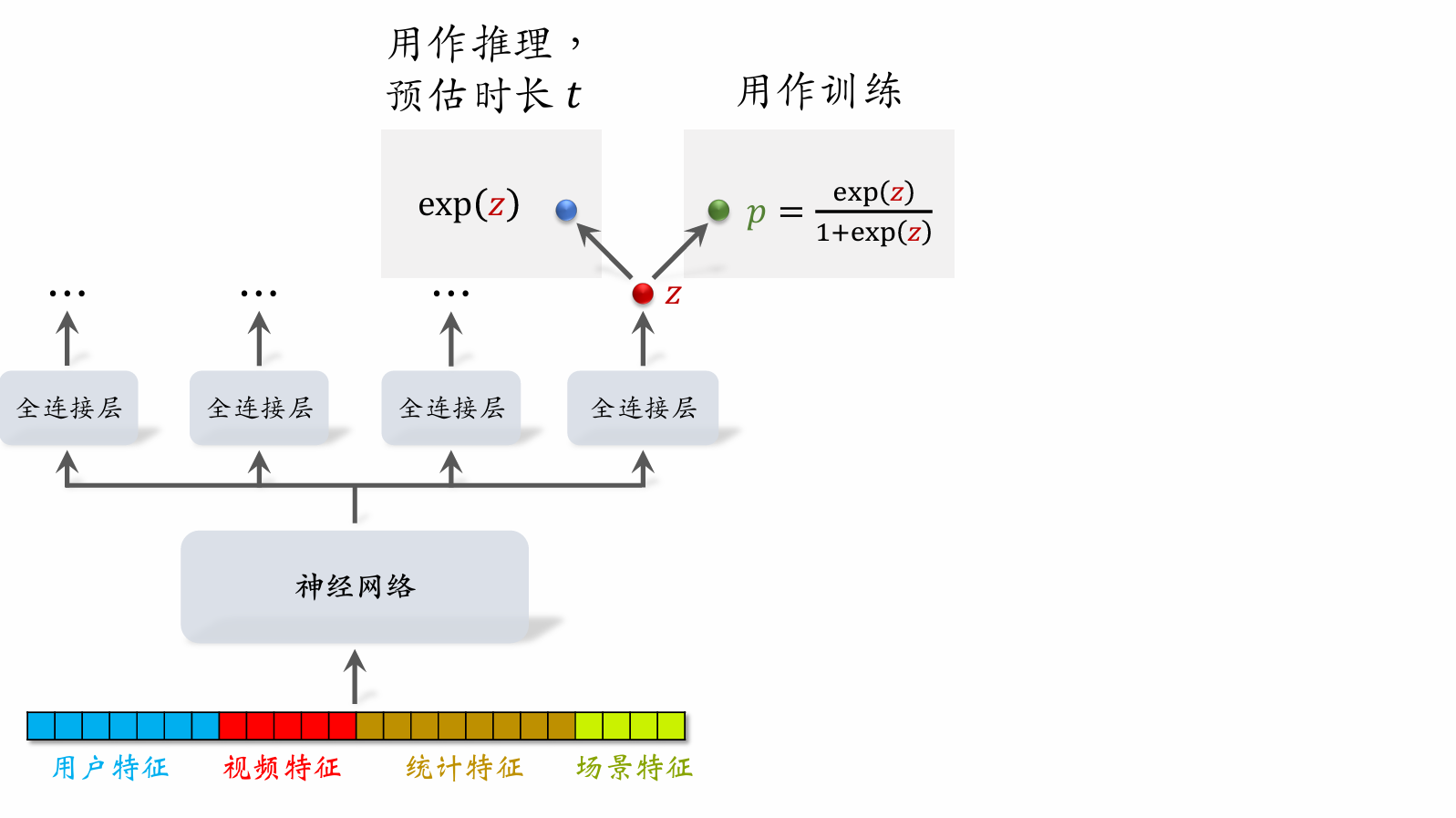 |
| 179 | + |
| 180 | +#### 视频播放时长建模 |
| 181 | + |
| 182 | +- 把最后一个全连接层的输出记作 $z$。设 $p = \text{sigmoid}(z)$。 |
| 183 | +- 实际观测的播放时长记作 $t$。(*如果没有点击,则 $t = 0$。*) |
| 184 | +- 做训练:最小化交叉熵损失 |
| 185 | + |
| 186 | +$$ |
| 187 | +\left( \frac{t}{1 + t} \cdot \log p + \frac{1}{1 + t} \cdot \log (1 - p) \right)。 |
| 188 | +$$ |
| 189 | + |
| 190 | +- 做推理:把 $\exp(z)$ 作为播放时长的预估。 |
| 191 | +- 把 $\exp(z)$ 作为融合公式中的一项。 |
| 192 | + |
| 193 | +#### 视频完播 |
| 194 | + |
| 195 | +**回归方法** |
| 196 | + |
| 197 | +- 例:视频长度 10 分钟,实际播放 4 分钟,则实际播放率为 $y = 0.4$。 |
| 198 | + |
| 199 | +- 让预估播放率 $p$ 拟合 $y$: |
| 200 | + |
| 201 | +$$ |
| 202 | +\text{loss} = y \cdot \log p + (1 - y) \cdot \log (1 - p)。 |
| 203 | +$$ |
| 204 | + |
| 205 | +- 线上预估完播率,模型输出 $p = 0.73$,意思是预计播放 $73 \%$ |
| 206 | + |
| 207 | +**二元分类方法** |
| 208 | + |
| 209 | +- 定义完播指标,比如完播 80%。 |
| 210 | +- 例:视频长度 10 分钟,播放 >8 分钟作为正样本,播放 <8 分钟作为负样本。 |
| 211 | +- 做二元分类训练模型:播放 >80% vs 播放 <80%。 |
| 212 | +- 线上预估完播率,模型输出 $p = 0.73$,意思是: |
| 213 | + |
| 214 | +$$ |
| 215 | +\mathbb{P}(\text{播放} > 80\%) = 0.73。 |
| 216 | +$$ |
| 217 | +
|
| 218 | +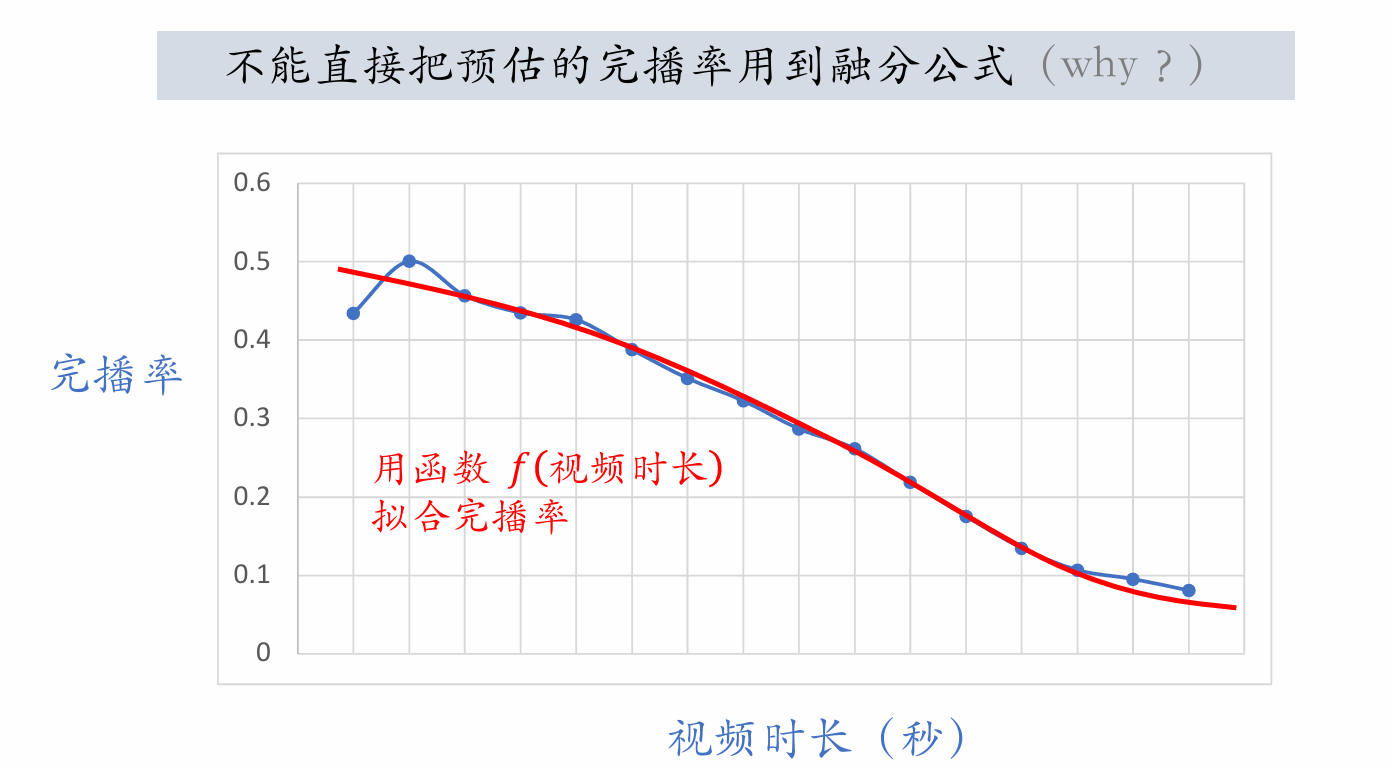 |
| 219 | +
|
| 220 | +视频越长完播率越低,直接用预估完播率会偏向推荐短视频而非长视频。因此需要进行优化,使短视频和长视频一样公平。 |
| 221 | +
|
| 222 | +- 线上预估完播率,然后做调整: |
| 223 | +
|
| 224 | + $$ |
| 225 | + p_{\text{finish}} = \frac{\text{预估完播率}}{f(\text{视频长度})} |
| 226 | + $$ |
| 227 | +
|
| 228 | +- 把 $p_{\text{finish}}$ 作为融合公式中的一项。 |
| 229 | +
|
| 230 | +### 排序模型的特征 |
| 231 | +
|
| 232 | +#### 特征 |
| 233 | +
|
| 234 | +**用户画像** (User Profile) |
| 235 | +
|
| 236 | +- 用户 ID(*在召回、排序中做 embedding*)。 |
| 237 | +- 人口统计学属性:性别、年龄。 |
| 238 | +- 账号信息:新老、活跃度⋯⋯ |
| 239 | +- 感兴趣的类目、关键词、品牌。 |
| 240 | +
|
| 241 | +**物品画像** (Item Profile) |
| 242 | +
|
| 243 | +- 物品 ID(*在召回、排序中做 embedding*)。 |
| 244 | +- 发布时间(*或者年齿*)。 |
| 245 | +- GeoHash(*经纬度编码*)、所在城市。 |
| 246 | +- 标题、类目、关键词、品牌⋯⋯ |
| 247 | +- 字数、图片数、视频清晰度、标签数⋯⋯ |
| 248 | +- 内容信息量、图片美学⋯⋯ |
| 249 | +
|
| 250 | +**用户统计特征** |
| 251 | +
|
| 252 | +- 用户最近 30 天(7 天、1 天、1 小时)的曝光数、点击数、点赞数、收藏数⋯⋯ |
| 253 | +- 按照笔记 *图文/视频* 分桶。(*比如最近 7 天,该用户对图文笔记的点击率、对视频笔记的点击率。*) |
| 254 | +- 按照笔记类目分桶。(*比如最近 30 天,用户对美妆笔记的点击率、对美食笔记的点击率、对科技数码笔记的点击率。*) |
| 255 | +
|
| 256 | +**笔记统计特征** |
| 257 | +
|
| 258 | +- 笔记最近 30 天(7 天、1 天、1 小时)的曝光数、点击数、点赞数、收藏数⋯⋯ |
| 259 | +- 按照用户性别分桶、按照用户年龄分桶⋯⋯ |
| 260 | +- 作者特征: |
| 261 | + - 发布笔记数 |
| 262 | + - 粉丝数 |
| 263 | + - 消费指标(*曝光数、点击数、点赞数、收藏数*) |
| 264 | +
|
| 265 | +**场景特征** (Context) |
| 266 | +
|
| 267 | +- 用户定位 GeoHash(*经纬度编码*)、城市。 |
| 268 | +- 当前时刻(*分段,做 embedding*)。 |
| 269 | +- 是否是周末、是否是节假日。 |
| 270 | +- 手机品牌、手机型号、操作系统。 |
| 271 | +
|
| 272 | +#### 特征处理 |
| 273 | +
|
| 274 | +- **离散特征**:做 embedding。 |
| 275 | + - 用户 ID、笔记 ID、作者 ID。 |
| 276 | + - 类目、关键词、城市、手机品牌。 |
| 277 | +
|
| 278 | +- **连续特征**:做分桶,变成离散特征。 |
| 279 | + - 年龄、笔记字数、视频长度。 |
| 280 | +
|
| 281 | +- **连续特征**:其他变换。 |
| 282 | + - 曝光数、点击数、点赞数等数值做 $ \log(1 + x) $。 |
| 283 | + - 转化为点击率、点赞率等值,并做平滑。 |
| 284 | +
|
| 285 | +#### 特征覆盖率 |
| 286 | +
|
| 287 | +- 很多特征无法覆盖 100% 样本。 |
| 288 | +- 例:很多用户不填年龄,因此用户年龄特征的覆盖率远小于 100%。 |
| 289 | +- 例:很多用户设置隐私权限,APP 不能获取用户地理定位,因此场景特征有缺失。 |
| 290 | +- 提高特征覆盖率,可以让精排模型更准。 |
| 291 | +
|
| 292 | +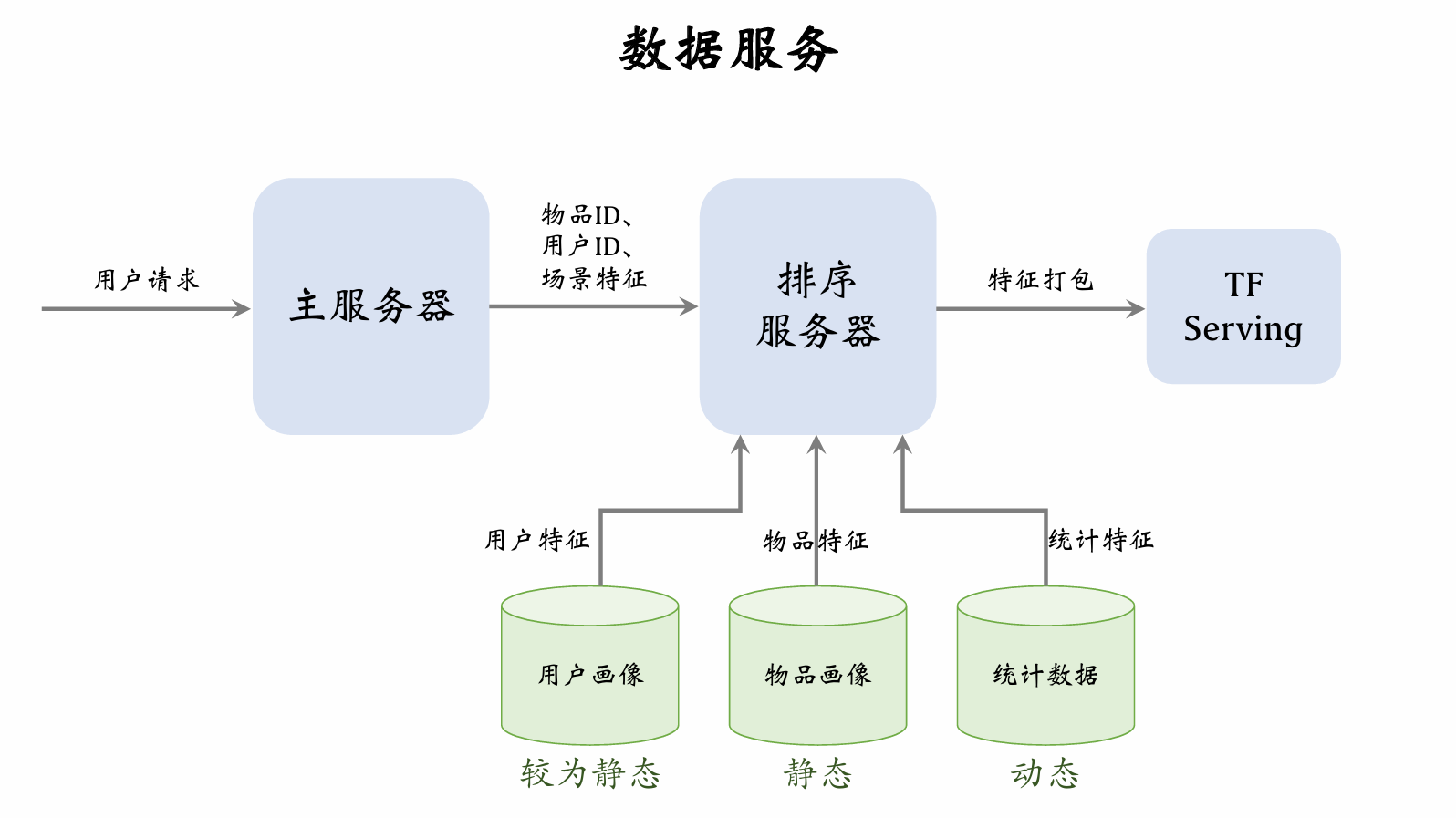 |
| 293 | +
|
| 294 | +主服务器从召回服务器召回一批物品ID。用户发送请求,主服务器将用户ID,场景特征以及物品ID发送给排序服务器。 |
| 295 | +
|
| 296 | +用户画像数据库压力较小,因为每次只读一个用户的特征。物品画像压力比较大,因为每次要读几千篇笔记的特征。同理,用户统计值数据库压力较小,物品统计值数据压力很大。用户画像的向量可以很大,但是物品画像的向量不要很大。 |
| 297 | +
|
| 298 | +用户画像以及物品画像都比较静态,甚至可以将用户画像和物品画像直接缓存在排序服务器本地。统计数据是动态的,需要及时更新数据库。 |
| 299 | +
|
| 300 | +排序服务器在收取到特征后,将特征打包给 TF Serving 。TF 会给笔记打分,将结果返回给排序服务器。排序服务器根据一系列规则给笔记排序,把排名最高的几十篇笔记返回给服务器。 |
| 301 | +
|
| 302 | +
|
| 303 | +
|
| 304 | +### 粗排 |
| 305 | +
|
| 306 | +**粗排 VS 精排** |
| 307 | +
|
| 308 | +| **粗排** | **精排** | |
| 309 | +| -------------------- | ------------------ | |
| 310 | +| 给几千篇笔记打分。 | 给几百篇笔记打分。 | |
| 311 | +| 单次推理代价必须小。 | 单次推理代价很大。 | |
| 312 | +| 预估的准确性不高。 | 预估的准确性更高。 | |
| 313 | +
|
| 314 | +#### 精排模型&双塔模型 |
| 315 | +
|
| 316 | +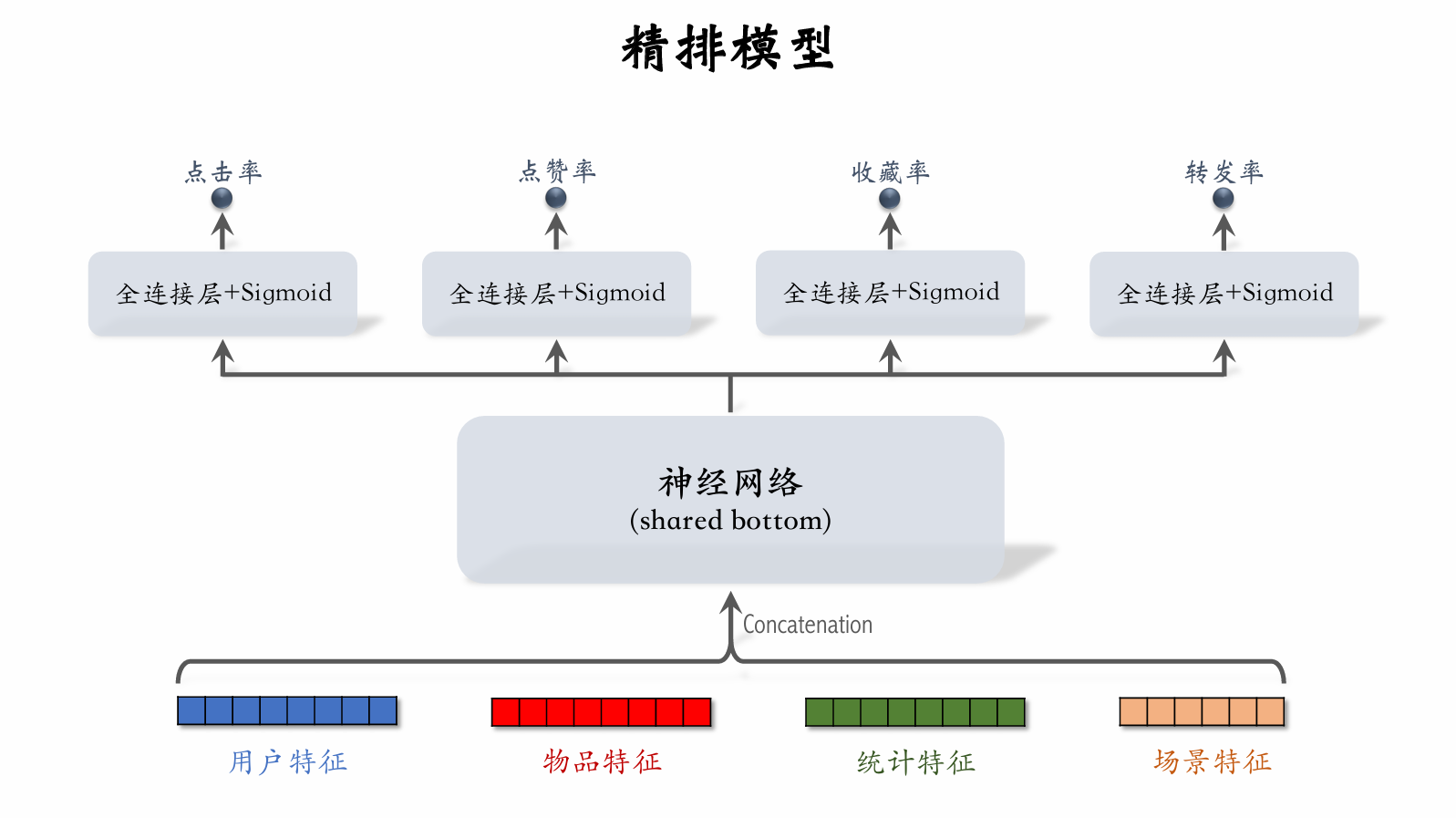 |
| 317 | +
|
| 318 | +**精排模型** |
| 319 | +
|
| 320 | +- 前期融合:先对所有特征做 concatenation,再输入神经网络。 |
| 321 | +- 线上推理代价大:如果有 $n$ 篇候选笔记,整个大模型要做 $n$ 次推理。 |
| 322 | +
|
| 323 | +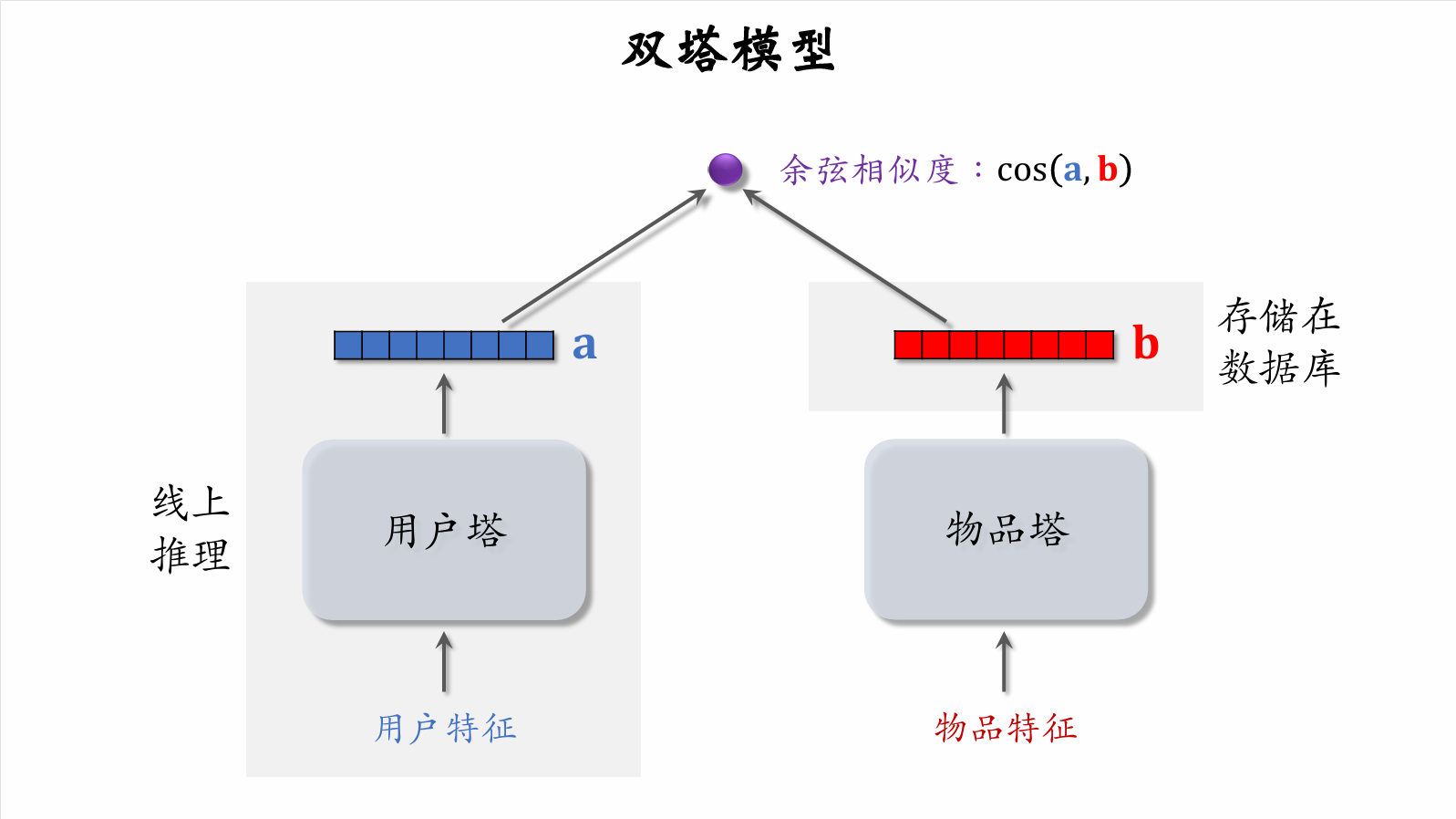 |
| 324 | +
|
| 325 | +**双塔模型** |
| 326 | +
|
| 327 | +- 后期融合:把用户、物品特征分别输入不同的神经网络,不对用户、物品特征做融合。 |
| 328 | +
|
| 329 | +- 线上计算量小: |
| 330 | + - 用户塔只需要做一次线上推理,计算用户表征 a。 |
| 331 | + - 物品表征 b 事先储存在向量数据库中,物品塔在线上不做推理。 |
| 332 | +
|
| 333 | +- 预估准确性不如精排模型。 |
| 334 | + 后期融合准确性不如前期融合 |
| 335 | +
|
| 336 | +#### 粗排的三塔模型 |
| 337 | +
|
| 338 | +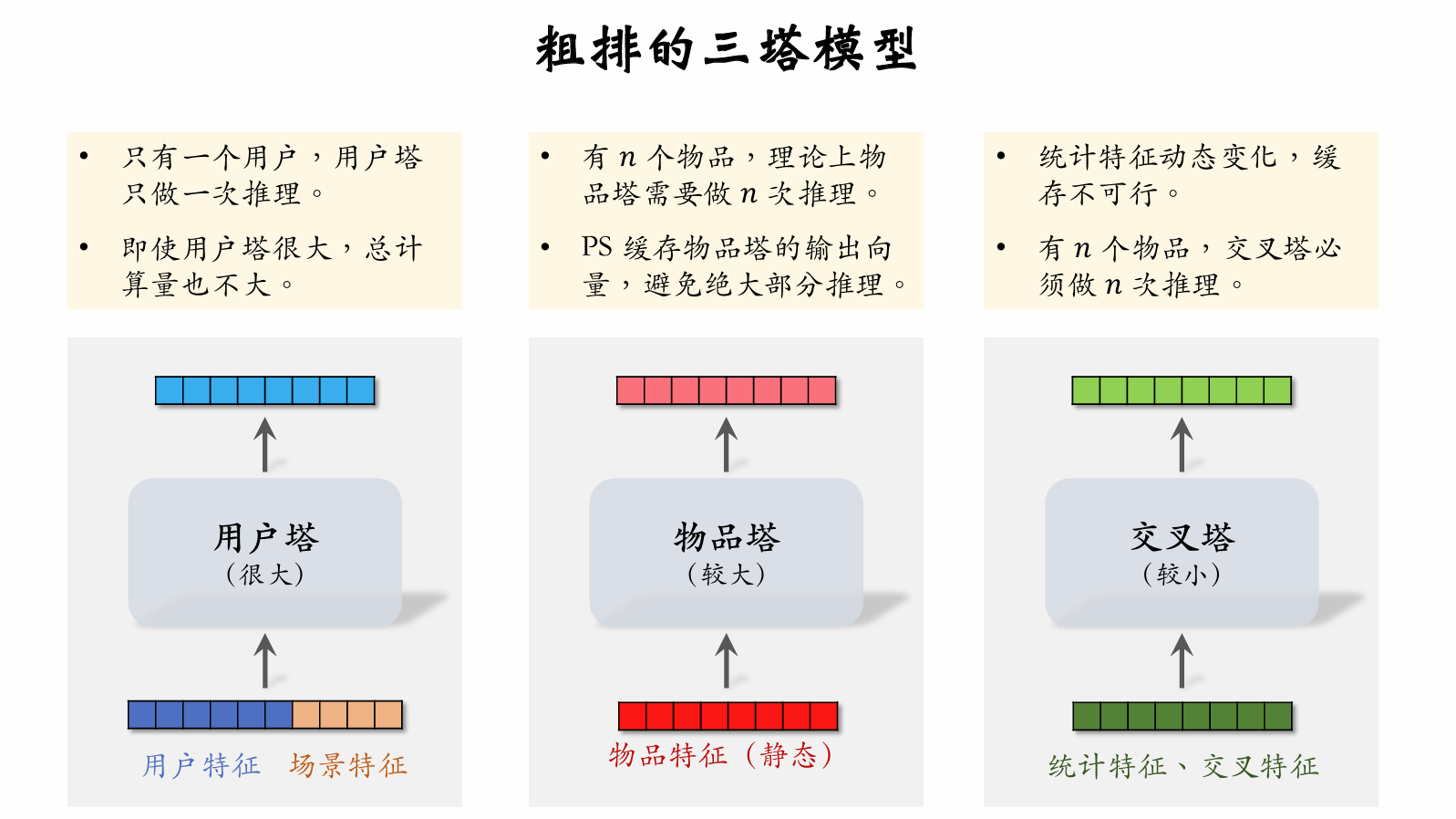 |
| 339 | +
|
| 340 | +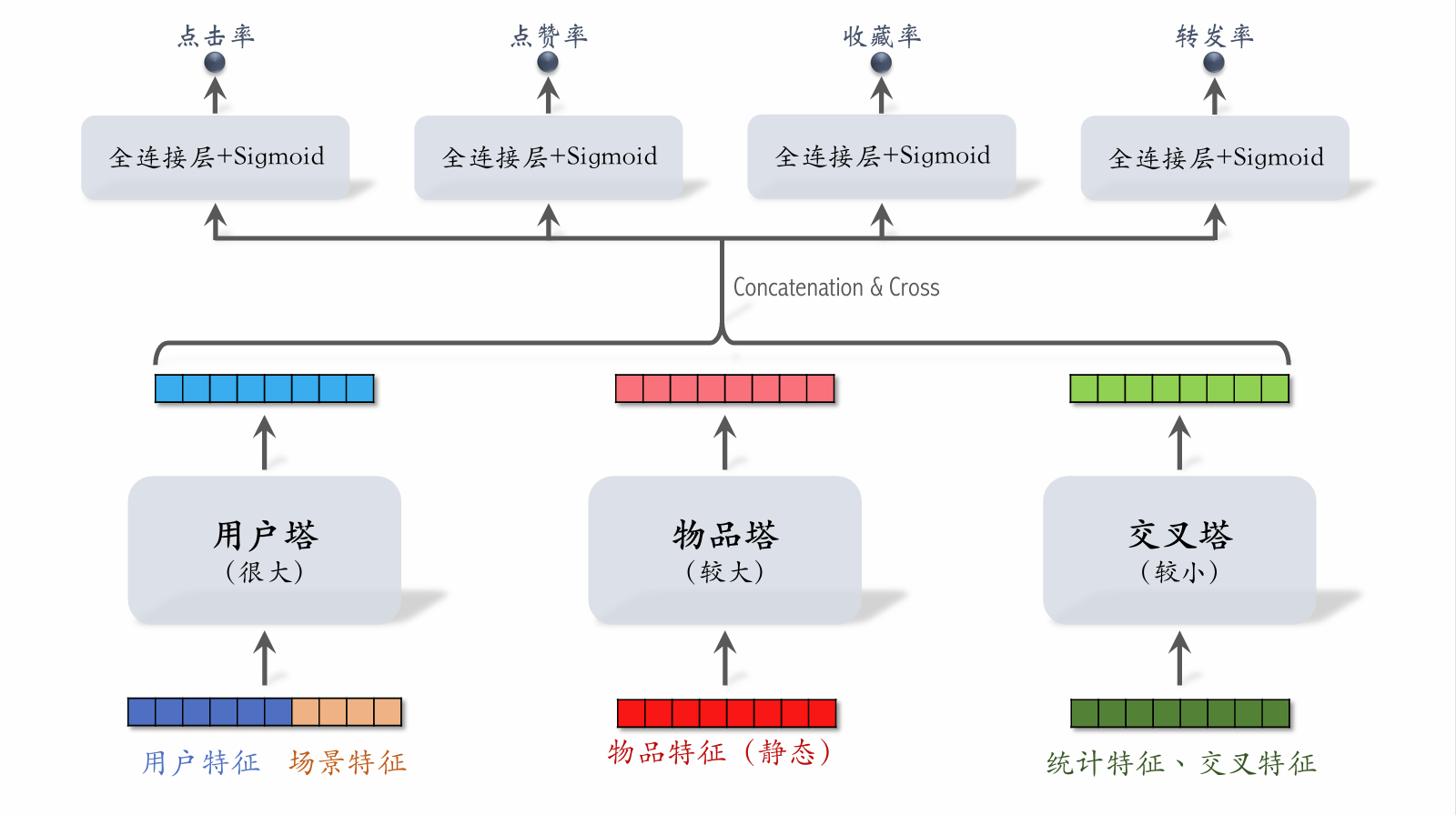 |
| 341 | +
|
| 342 | +- 有 $n$ 个物品,模型上层需要做 $n$ 次推理。 |
| 343 | +- 粗排推理的大部分计算量在模型上层。 |
| 344 | +
|
| 345 | +**三塔模型的推理** |
| 346 | +
|
| 347 | +- 从多个数据源取特征: |
| 348 | + - 1 个用户的画像、统计特征。 |
| 349 | + - $n$ 个物品的画像、统计特征。 |
| 350 | +
|
| 351 | +- 用户塔:只做 1 次推理。 |
| 352 | +- 物品塔:未命中缓存时需要做推理。 |
| 353 | +- 交叉塔:必须做 $n$ 次推理。 |
| 354 | +- 上层网络:做 $n$ 次推理,给 $n$ 个物品打分。 |
| 355 | +
|
| 356 | +
|
0 commit comments