각 폴더에 해당하는 과목의 이론을 정리했습니다.
특정 과목에 해당하는 지식 확인 시 해당 폴더로 접속
Ctrl+F를 사용할려면 이 페이지에서 확인
코딩 테스트에서는 잘 사용해도 정의에 대해 설명을 professional하게 하지 못하는 경우를 방지하기 위해 각 알고리즘의 정의를 기록 동빈나님의 알고리즘 강의 및 구글링 참조
-
그래프에서 깊은 부분을 우선적으로 탐색하는 알고리즘
-
탐색 시작 노드에서 다음 분기로 넘어가기 전에 해당 분기를 완벽하게 탐색하는 방식
-
스택 자료구조 or 재귀 함수를 사용하며 구체적인 동작은 아래와 같음
-
탐색 시작 노드를 스택에 삽입하고 방문 처리
-
스택의 최상단 노드에 방문하지 않은 인접한 노드가 하나라도 있으면 그 노드를 스택에 넣고 방문 처리
방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼냄 -
더 이상 2번 과정을 수행할 수 없을 때까지 반복
-
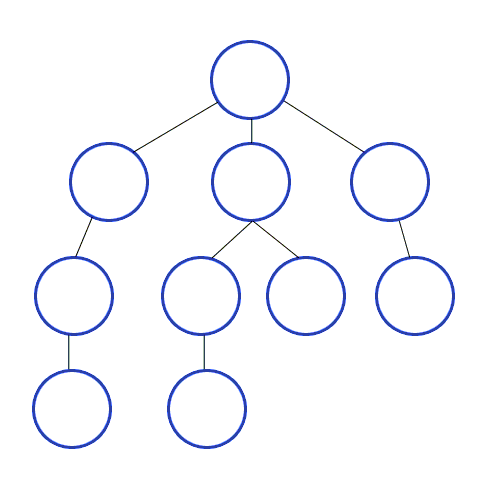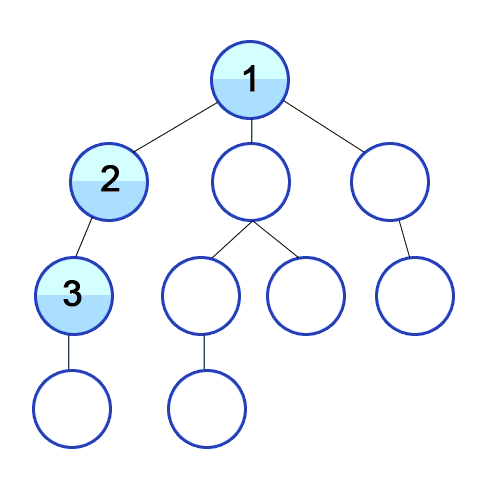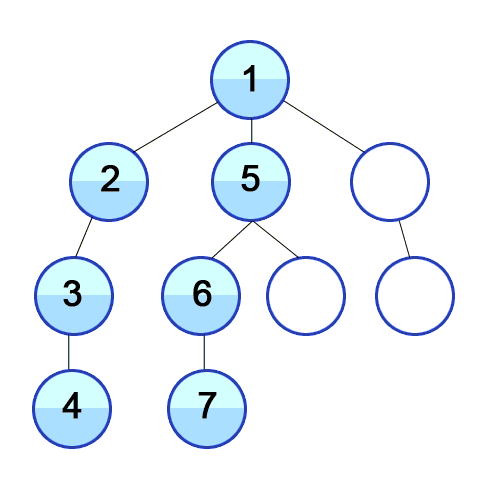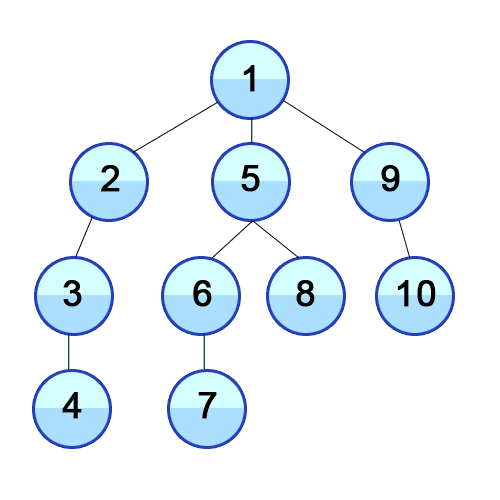
-
그래프에서 가까운 노드부터 우선적으로 탐색하는 알고리즘
-
탐색 시작 노드에서 시작해서 인접한 노드를 먼저 탐색하는 방식
-
Queue 자료구조를 사용하며 구체적인 동작은 아래와 같음
-
탐색 시작 노드를 큐에 삽입하고 방문 처리
-
큐에서 노드를 꺼낸 후 해당 노드의 인접 노드 중 방문하지 않은 노드를 모두 큐에 삽입 및 방문처리
-
더 이상 2번 과정을 수행할 수 없을 때까지 반복
-
-
특정한 노드에서 출발하여 모든 노드로 가는 최단 경로를 계산하는 알고리즘
-
음의 간선이 없을 때 동작
-
그리디 알고리즘에 속함
-
최단경로 계산 시 현재 노드에서부터 다른 노드 각각에 대한 최단 거리를 1차원 리스트에 저장하여 갱신
-
노드와 간선 수가 많을 때 다익스트라, 노드의 개수가 적을 때는 플로이드 워셜 알고리즘이 효과적
-
힙 자료구조 사용 시 시간복잡도 O(ElogV) (E : 최대 간선의 갯수, V : 노드의 갯수)
-
출발 노드 선택 후 최단 거리 테이블 출발 노드를 제외한 모든 값을 무한으로 초기화
-
방문하지 않은 노드 중 최단 거리 테이블 내 최단 거리에 있는 노드 선택
-
선택한 노드를 거쳐 다른 노드로 가는 거리 각각 계산
-
최단 거리 테이블 내 노드별 거리가 계산한 값보다 클 경우 계산한 값으로 갱신
-
2번~4번 과정 불가능할 때까지 반복
-

(출처 https://www.youtube.com/watch?v=F-tkqjUiik0&list=PLVsNizTWUw7H9_of5YCB0FmsSc-K44y81&index=30)
-
모든 노드에서 다른 모든 노드로 가는 최단 경로를 계산하는 알고리즘
-
다이나믹 프로그래밍 유형에 속함
-
최단경로 계산 시 최단 거리를 2차원 리스트에 저장하여 갱신
-
노드와 간선 수가 많을 때 다익스트라, 노드의 개수가 적을 때는 플로이드 워셜 알고리즘이 효과적
-
각 단계마다 특정한 노드 k를 거쳐 가는 경우 확인
-
최단 거리 2차원 테이블 초기화
-
1번 노드를 거쳐가는 경우를 고려하여 테이블 갱신 ~ n번 노드를 거쳐가는 경우를 고려한 테이블 갱신
-
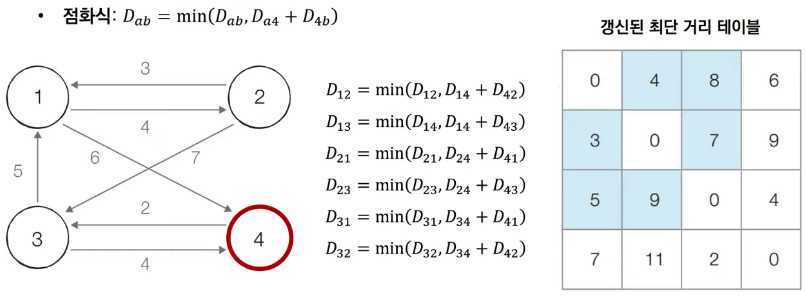
(출처 https://www.youtube.com/watch?v=hw-SvAR3Zqg&list=PLVsNizTWUw7H9_of5YCB0FmsSc-K44y81&index=31)
-
두 노드가 같은 그래프에 속하는지 판별하는 알고리즘
-
서로소 집합, 상호 베타적 집합(Disjoint_Set)으로도 불림
-
루트 노드를 찾는 Find 연산과 노드를 합치는 Union 연산(두 노드의 루트 노드를 비교하여 한쪽으로 합침)으로 구성
[Example]
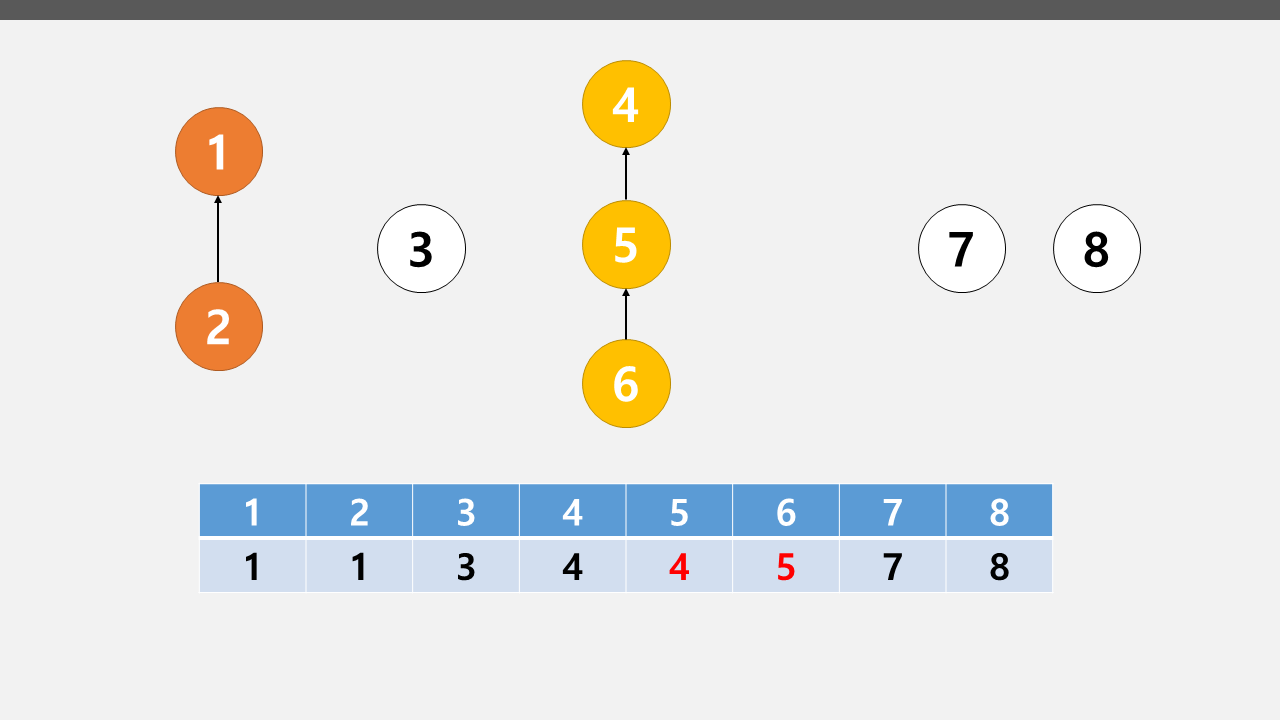
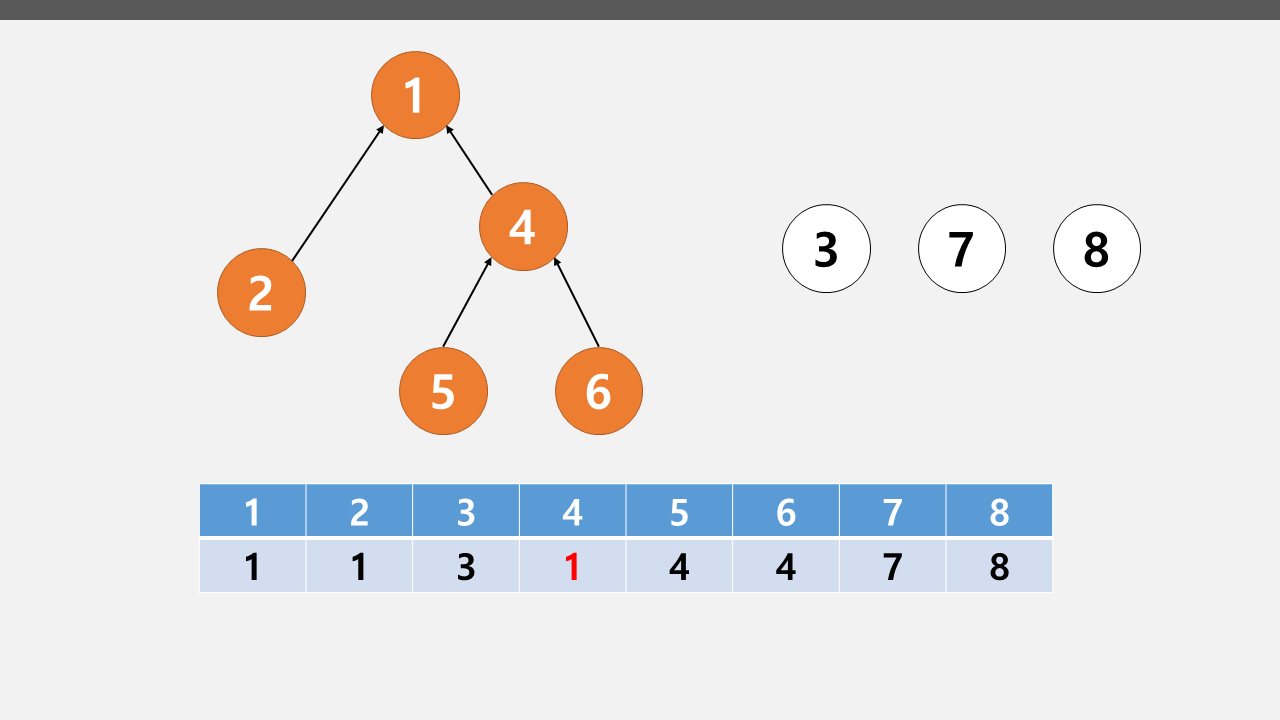 (출처 https://ip99202.github.io/posts/%EC%9C%A0%EB%8B%88%EC%98%A8-%ED%8C%8C%EC%9D%B8%EB%93%9C(Union-Find)/)
(출처 https://ip99202.github.io/posts/%EC%9C%A0%EB%8B%88%EC%98%A8-%ED%8C%8C%EC%9D%B8%EB%93%9C(Union-Find)/)
-
최대값 혹은 최소값을 빠르게 찾기 위한 이진 트리
-
최소 힙은 부모가 자식보다 작음
-
최대 힙은 부모가 자식보다 큼
-
힙의 삽입과 삭제는 LogN만큼의 시간복잡도를 가짐
-
왼쪽 자식은 부모보다 작고 오른쪽 자식은 부모보다 큰 이진 트리
-
삽입, 검색, 삭제가 모두 트리의 높이인 logN~N만큼의 시간복잡도 가짐
-
그래서 트리가 편향되지 않기 위해 자가 균형 트리 사용
-
이진 탐색 트리는 시간복잡도가 트리의 높이에 따라 결정되므로 편향될 경우 효율이 떨어짐
-
편향되지 않게 삽입과 삭제를 개선한 이진 탐색 트리가 자가 균형 트리
-
AVL 트리와 Red Black 트리가 있음
-
해시에 매핑하여 데이터를 저장하는 자료구조
-
키는 해시 함수를 통해 해시로 변경된 다음 value와 매핑이 되어 bucket에 저장
-
시간복잡도는 삽입, 삭제, 조회 모두 1
-
해시에서 하나의 버킷에 여러개의 데이터가 들어갈때 개방주소법과 체이닝을 통해 충돌 회피
-
개방주소법 : 다른 해시값에 저장하는 방법
-
체이닝 : 해쉬테이블이 원소 하나를 담는게 아니라 링크드 리스트를 담는 방법
-
-
데이터베이스 내 데이터에 접근하도록 도와주는 시스템
-
크게 질의처리기와 저장시스템으로 이루어짐
-
데이터베이스의 무결성과 일관성을 위해 ACID를 만족해야함
-
원자성 : 한 트랜잭션 내 실행 작업은 모두 반영하거나 모두 반영하지 않아야 한다.
-
일관성 : 작업 처리 결과는 항상 일관적이어야 한다.
-
독립성 : 동시에 실행되는 트랜잭션은 서로에게 영향을 끼치지 않아야 한다.
-
지속성 : 트랜잭션 완료시 결과가 영구적으로 반영
-
-
SQL을 보완한다는 의미를 가짐
-
스키마가 없어서 데이터를 조회하고 삽입하는 속도가 빠름
-
대량의 분산 데이터를 저장하는데 특화됨
-
테이블을 컬럼 단위로 나누는 기법
-
update나 insert 같은 작업이 분산되어서 성능이 향상
-
테이블간 join 비용 증가
-
index를 별도로 파티셔닝할 수 없음
-
테이블을 row 단위로 분산해서 저장하는 방법
-
샤드 키를 정하는 방법에 따라서 샤드 종류가 결정
-
크게 해시 샤딩(해시키 이용)과 동적 샤딩(로케이터 서비스 이용)이 있음
-
정규화
-
테이블을 분할하여 중복 데이터를 제거함으로써 데이터 무결성을 유지하는 행위
-
1정규화(1NF) : 도메인이 원자값

-
2정규화(2NF) : 부분적 함수 종속 제거

-
3정규화(3NF) : 이행적 함수 종속 제거

-
BCNF(보이스코드 정규화) : 결정자이면서 후보키가 아닌 것을 제거
-
교수는 과목을 결정 짓는 결정자
-
교수는 학번을 결정 지을 수 없으므로 후보키가 아님, 제거 대상
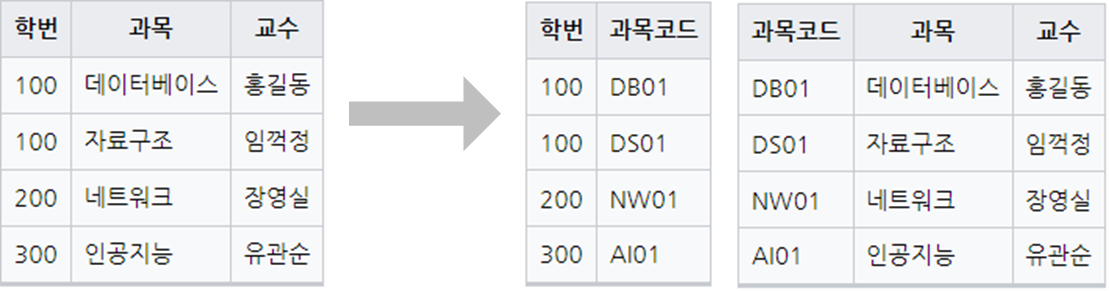
-
-
4정규화(4NF) : 다치(다중) 종속 제거
- 다치종속 : 두개의 독립된 애트리뷰트가 1:N 관계로 대응하는 관계

-
5정규화(5NF) : 조인 종속 제거
- Join 종속 : 하나의 릴레이션을 무손실, 비부가적 분해하고 나서 다시 합쳤을 때 원래의 릴레이션으로 복원 가능한 관계

-
-
비정규화
- 데이터베이스 성능 향상 등을 위해 중복, 통합, 분리 등을 수행하여 의도적으로 정규형을 위배한 데이터 구조로 만드는 행위
-
데이터 정의어(DDL, Data Definition Language)
-
테이블과 컬럼을 정의하는 명령어로 생성, 수정, 삭제 등의 데이터 전체 골격을 결정하는 언어
-
ex. CREATE, ALTER, DROP, RENAME, TRUNCATE
-
-
데이터 조작어(DML, Data Manipulation Language)
-
데이터베이스의 내부 데이터를 관리하기 위한 언어로 데이터를 조회, 추가, 변경, 삭제 등의 작업을 수행
-
SELECT, INSERT, UPDATE, DELETE
-
-
데이터 제어어(DCL, Data Control Language)
-
데이터베이스에 접근하고 객체들을 사용하도록 권한을 주고 회수하는 명령
-
GRANT, REVOKE
-
-
트랜잭션 제어어(DDL, Transaction Control Language)
-
데이터를 제어하는 언어가 아닌 DML에 의해 조작된 결과를 논리적인 작업 단위로 묶어 트랜잭션 별로 제어
-
COMMIT, ROLLBACK, SAVEPOINT
-
-
과거 소프트웨어 개발 과정에서 발견한 설계 노하우를 패턴으로 정리한 것
-
범용적인 코드스타일로 의사소통을 효율적으로 할 수 있음
-
이미 검증된 구조이므로 설계를 빠르게 할 수 있음
-
목적에 따라서 생성패턴, 구조패턴, 행위패턴으로 나뉘게 됨
-
인스턴스를 오직 1개만 생성하는 패턴
-
예를 들면 DB 커넥션이나 스레드 풀 객체를 생성할 때 사용
-
만드는 방법으로 이른 초기화 방식, 게으른 초기화 방식, Holder에 의한 초기화 방식이 있음
-
객체를 직접 생성하지 않고 객체를 생성하는 팩토리 객체를 사용하는 패턴
-
직접 객체를 생성하는 것을 막아줘서 결합도를 낮춰주는 효과
-
어댑터를 사용해서 호환되지 않는 인터페이스를 호환하도록 하는 패턴
-
향후 인터페이스가 바뀌더라도 변경된 내용이 어댑터 안에 캡슐화되므로 수정할 필요가 없음
-
상속을 통해서 부모 클래스의 기능을 확장할 때 사용
-
부모 클래스에서 변하지 않는 기능을 구현
-
자식 클래스에서 확장할 기능을 구현
-
자바에서는 추상 클래스를 사용해서 구현
-
대표적으로 AbstractMap이 있음
-
AbstractMap에서 공통된 기능을 정의
-
상속받은 HashMap이나 TreeMap에서 각각의 자료구조에 맞게 get() 메소드를 다르게 구현
-
-
xml
-
주석 가능,
-
사소한 오타는 괜찮음
-
구조가 올바른지 스키마를 통해 검증 가능(xsd)
-
안정성 중시
-
-
json
-
가독성 유지보수 용이
-
사소한 오타 불가능
-
직접 검증 코드를 만들어야함
-
가벼움 중시
-
-
yaml
-
줄바꿈과 들여쓰기를 통해 데이터 표현
-
주석 가능
-
상속을 사용하여 여러 데이터 표현 가능
-
-
브라우저 호환성 관리
-
퍼포먼스가 좋지 않음(무거움)
-
react 등 좋은 대안이 많으며 브라우저 호환성도 개선되었기 때문에 잘 사용하지 않음
-
서버와 비동기적으로 데이터를 주고받는 자바스크립트 기술
-
새로고침없이 서버에게 get요청하는 JS코드
-
웹페이지 전환없이 부드럽게 전개
-
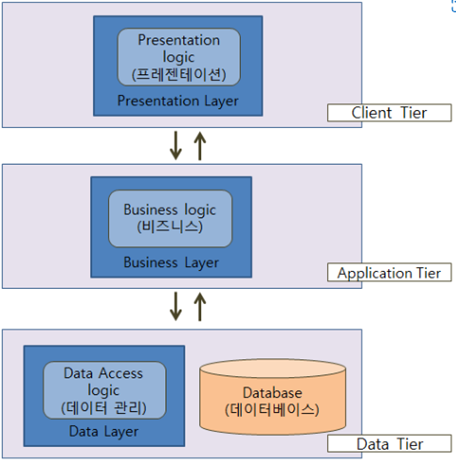
특정 플랫폼을 역할을 구분하여 3계층으로 나눈 구조
-
각 계층의 변경이 다른 계층이 의존하지 않음(독립적)
-
프레젠테이션 계층 (Presentation Tier), 어플리케이션 계층 (Application Tier), 데이터 계층 (Data Tier)으로 구분되어 있음
-
프레젠테이션 계층 (Presentation Tier)
-
UI를 지원하며 프론트엔드라고도 부름
-
주로 정적인 데이터를 다루는 웹서버가 해당되며 HTML, Javascript, CSS 등이 이 계층에 해당
-
-
어플리케이션 계층 (Application Tier)
-
사용자가 요청하는 정보를 연산 등을 통해 가공하는 역할
-
비즈니스 로직 계층, 트랜잭션 계층, 미들웨어 또는 백엔드이라고도 부름
-
주로 동적인 데이터를 다루는 WAS가 해당되며 Java, Python 등이 이 계층에 해당
-
-
데이터 계층 (Data Tier)
-
데이터베이스에 접근하여 데이터를 읽거나 쓰는 것을 관리하는 역할
-
주로 DBMS가 이 계층에 해당되며 백엔드라고도 부름
-
MySQL, MongoDB, MariaDB, Oracle 등이 이 계층에 해당
-
-
컨테이너화된 애플리케이션들이 단일 운영체제상에서 실행되도록 해주는 기술
-
환경을 구축하는 등 과정을 컴퓨터가 자동으로 재현할 수 있게 하는 Tool
-
도커의 원리
-
각 요소들이 설치된 모습을 이미지로 박제하여 저장
-
도커 이미지들은 도커허브에 업로드 되어 공유
-
이미지로 저장된 항목들이 함께 연결되어 동작하도록 설정된 상태를 명령어 텍스트나 문서 형태로 저장
-
독립된 가상 환경인 컨테이너를 이용하여 구축한 것들을 복원
-
-
가상 컴퓨팅은 물리적 컴퓨터 안에 각각 OS를 가동하는 가상 컴퓨터들이 물리적 자원을 분할해서 사용
-
도커는 OS단에 내려가지 않고 실행환경만 독립적으로 구동
(컴퓨터에 직접 요소들을 설치한 거랑 별차이없는 성능이 가능하고 가상컴퓨팅보다 훨씬 가볍고 빠름) -
서버를 고치거나 업그레이드 할때 컨테이너만 교체하여 실행
-
도커 사용
-
서버를 돌리기 위한 환경을 구축하기 위해 언어, 데이터베이스, WAS, 자동배포툴 등등 여러가지를 버전을 신경써서 다운받은 후
서로 잘 맞물려 동작할 수 있도록 설정하는 경우 -
같은 서버에 여러 서비스를 돌리는 경우에 사용
-
각각 다른 실행환경(Tool의 버전이 다른 경우, 윈도우 -> 리눅스)에서 동작해야 할 때 사용
-
더 성능 좋은 서버로 옮기거나 늘어난 접속량을 처리하기 위해 서버를 여럿 추가하여 이전 설치환경을 서버마다 구축해야 하는 경우
-
-
컨테이너를 관리하기 위한 Tool
-
컨테이너에 대한 모니터링을 실시하여 컨테이너가 죽으면 자동 재시작하는 기능
-
사용자가 급증하는 경우 자동으로 새로운 컨테이너 생성
-
컨테이너 버그나 버전을 업데이트하는 경우 웹사이트 다운되는 경우없이 차례대로 조치
-
개발(Development) + 운영(Operation)을 결합해 탄생한 개발 방법론
-
시스템 개발자와 운영을 담당하는 정보기술 전문가 사이의 소통, 협업, 통합과 자동화를 강조하는 소프트웨어 개발 방법론
-
스크럼, 애자일 개발 등 계획과 문서를 기반으로 개발 모형이나 모델에 따라 앞을 예측하며 개발하는 것이 아닌
실질적인 코딩을 기반으로 일정한 주기에 따라 계속적으로 프로토 타입을 형성하고 필요한 요구사항을 파악하며
이에 따라 즉시 수정사항을 적용하여 결과적으로 하나의 큰 소프트웨어를 개발하는 적응형 방법도 사용됨 -
CI/CD(지속적 통합/지속적 배포, Continuous Integration/Continuous Deployment)
-
CI는 개발을 진행하면서 품질을 관리할 수 있도록 하는 것
-
여러 명이 하나의 코드에 대해서 수정을 진행해도 지속적으로 통합하여 관리할 수 있음을 의미
-
빌드/테스트 자동화를 통해 수정한 코드를 브랜치에 병합하기만 하면 자동으로 빌드와 테스트 검증
-
CD는 소프트웨어가 항상 신뢰가능한 수준으로 배포될 수 있도록 관리하자는 개념
-
CD는 빌드 및 테스트 병합까지 성공적이면 github와 같은 저장소에 업로드 하는 지속적 제공으로도 사용됨
-
성공적으로 병합된 내역을 저장소 뿐만 아니라 사용자가 사용할 수 있는 배포환경까지 릴리즈하는 것을 의미
-
- 결과의 변경없이 코드의 구조를 재조정하여 가독성을 높이고 유지보수를 수월하게 함
-
컴파일러가 자바 소스를 바이트 코드로 변환
-
클래스 로더가 바이트 코드를 런타임 데이터 영역에 로드
-
로딩된 바이트 코드가 실행엔진에 의해서 실행
-
스레드마다 pc 레지스터, jvm stack, native method stack으로 구성
-
pc 레지스터 : 현재 수행중인 jvm 명령어가 들어있음
-
jvm stack : 호출된 메소드의 매개변수, 지역변수, 리턴정보들이 저장
-
native method stack : 자바 외의 언어인 C나 C++ 같은 것들을 수행하기 위한 영역
-
-
스레드 공통으로 heap과 메소드 영역으로 구성
-
메소드 영역 : 클래스 별로 전역변수, 정적 변수, 메소드 정보들이 저장
-
heap 영역 : 런타임 중 생성되는 객체들(new로 생성된 인스턴스 등)이 동적으로 할당되는 곳
-
-
GC는 JVM에서 메모리를 관리해주는 모듈
-
heap 메모리를 재사용하기 위해서 더 이상 참조되지 않는 객체들을 메모리에서 제거하는 모듈
-
개발자가 직접 메모리를 정리하지 않아도 되서 개발속도가 향상되는 장점
-
Mark and Sweep이라는 과정에서 참조되지 않는 객체를 찾는 과정에서 스레드가 잠깐 중단되므로 성능이 떨어짐
-
현실 세계의 사물과 같은 객체를 만들고 그 객체에서 필요한 특징을 뽑아서 프로그래밍을 수행
-
추상화 캡슐화 다형성 상속 특징이 있음
-
추상클래스
-
abstract 지시자로 정의되어서 추상메소드가 하나 이상 포함되는 클래스
-
상속받아서 기능을 재활용하고 확장시키는 목적
-
-
인터페이스
-
interface 지시자로 정의되어서 모든 메소드가 추상메소드로 정의
-
함수의 구현을 강제해서 구현한 객체들이 같은 동작을 하는 것을 보장하는 것에 목적
-
-
객체 : 소프트웨어 세계에 구현할 대상, 클래스로부터 만들어지는 실체, 클래스로 선언된 변수
-
클래스 : 객체를 만들어 내기 위한 설계도 또는 틀, 만들어 낼 객체의 속성과 메서드의 집합을 담아놓은 것
-
인스턴스 : 설계도(클래스) 바탕으로 구현해야할 대상(객체)가 구현된 구체적인 실체, 객체가 메모리에 할당된 상태이며 런타임에 구동되는 객체
-
깊은 복사(Deep Copy, Call by value)
-
새로운 메모리 공간을 만들어서 실제 값을 복사
-
실제 값과 복사 값이 서로 다른 메모리에 저장
-
-
얉은 복사(Shallow Copy, Call by reference)
-
객체의 주소값을 복사하는 방식으로 원본에 영향을 줄 수 있음
-
실제값과 복사 값이 동일한 메모리 참조
-
-
배열
- 크기가 고정
-
리스트
-
크기가 가변적
-
크기를 증가시킬 때 기존 배열을 복사해서 새로운 배열로 옮기는 방식
-
늘어난 용량 = 기존용량 + 기존용량//2
-
-
HashMap
-
싱글 스레드 방식
-
Key 값으로 null 허용
-
-
HashTable
-
멀티 스레드 방식
-
Key 값으로 null 제한
-
동기화 처리로 속도 느림
-
출처 : https://mundol-colynn.tistory.com/133
| 구분 | 선언위치 | 초기화 | 접근 | 메모리영역 | 생명주기 | |
|---|---|---|---|---|---|---|
| 전역변수 | 멤버변수 | 클래스 블럭 내 선언 | 자동 초기화 | 클래스 내부의 모든 메서드에서 사용 가능 | HEAP | 객체가 생성될 때 할당, 객체 소멸 시 소멸 |
| 전역변수 | 클래스변수 | 클래스 블럭 내 static 키워드를 붙여 선언 | 자동 초기화 | 클래스 내부의 모든 메서드에서 사용 가능 | Static | 프로그램 시작 시 할당, 종료 시 소멸, 객체 생성없이 사용가능 |
| 지역변수 | 지역변수 | 메서드 블럭 내 선언 | 초기화 필수(수동 초기화) | 선언된 블록 내부에서만 사용 가능 | Stack | 블록 내부 실행 종료 시 소멸 |
-
멤버변수
-
클래스 영역에 선언되는 변수
-
클래스 내부의 모든 메소드에서 공통적으로 사용 가능
-
다른 메소드에서도 값을 유지하면서 사용할 필요가 있을 때 사용
-
메모리가 할당될 때부터 프로그램 종료될 때까지 유지되므로, 메모리 낭비 발생
-
다른 메소드에서 함부로 변경 시 오류 발생
-
-
클래스 변수
-
클래스 영역에 선연되는 변수
-
static 키워드를 사용하여 선언
-
해당 클래스의 인스턴스들 사이에서 값을 공유할 수 있음
-
인스턴스를 생성하지 않고도 사용 가능
-
인스턴스마다 변수가 생성되는 것을 방지하여 메모리 절약할 수 있으므로, 값을 유지해야하는 상황에 유용
-
클래스의 구조를 나타내는 데 사용되는 상수나 플래그 등을 저장할 때 사용
-
전역변수와 같이 프로그램 전체에서 메모리를 사용하므로 낭비를 줄이기 위해 적절한 사용 필요
-
-
지역 변수
-
메소드 내부에서 선언되는 변수로서, 해당 메소드 내부에서만 사용 가능
-
메소드가 실행될 때 메모리에 할당되고, 메소드가 종료될 때 메모리에서 제거
-
메모리를 효율적으로 사용 가능
-
해당 메소드 내부에서만 사용되므로 다른 메소드에서 함부로 변경될 우려가 없음
-
-
클래스나 메소드를 작성할 때, 데이터 타입을 미리 지정하지 않고 사용할 때, 타입을 지정할 수 있게 해주는 기능
-
코드 재사용성이 높아지고 컴파일 시 타입 안정성을 확보
-
즉 특정 타입의 객체만 저장하도록 제한할 수 있음
-
예를 들어 String말고 Object를 사용하면 Object를 꺼낼 때, Object 타입으로 꺼내지게 되고 추가적인 작업을 위해 형 변환이 필요
-
추가적인 작업이 Integer타입으로 짜여져 있을때, 값이 String 타입이면 에러 발생
-
추가적인 형 변환없이 명확하게 원하는 타입만 저장하기 위해 사
-
인터넷 환경에서 통신하기 위해 네트워킹에 대한 표준을 7계층으로 나눈 것
-
물리 계층, 데이터링크 계층, 네트워크 계층, 전송 계층, 세션 계층, 표현 계층, 응용 계층
-
물리
- 데이터를 전기적인 신호로 변환하여 전송하는 기능 수행
-
데이터링크
-
같은 네트워크에 있는 여러 대의 컴퓨터들이 데이터를 주고받기 위해 필요한 모듈
-
물리 계층으로 송수신된 정보를 관리하여 안전하게 전달되도록 지원(송수신 확인)
-
MAC 주소를 통한 통신
-
-
네트워크
- 라우터를 통해 패킷을 네트워크 간 IP를 사용하여 데이터 전송
-
전송
-
포트 번호를 사용하여 도착지 컴퓨터의 최종 도착지인 프로세스까지 데이터가 도달하게 하는 모듈
-
두 host 시스템으로부터 발생하는 데이터 흐름을 제공(TCP, UDP를 통해 통신을 활성화)
-
-
세션
- 데이터가 통신하기 위한 논리적 연결을 담당하며 TCP/IP 세션을 만들고 없애는 책임
-
표현
- 데이터 표현에 대한 독립성을 제공하고 암호화하는 역할(파일,인코딩 명령어를 포장, 압축)
-
응옹
- 사용자가 네트워크에 접근할 수 있도록 서비스 제공
-
TCP
-
신뢰성 있는 통신을 위해 사용하는 프로토콜로 높은 신뢰성을 보장하지만 UDP보다 속도는 느림,
-
3way 4way handshake로 서버와 클라이언트가 1:1 통신
-
흐름제어(수신자 버퍼 오버플로우 방지), 혼잡제어(네트워크 내 패킷 수가 과도하게 증가하는 현상 방지)
-
-
UDP
-
비연결형 프로토콜로, 손상된 데이터에 대해서 재전송하지 않음
-
신뢰성을 낮지만 TCP보다 속도가 빨라 스트리밍같은 서비스에 주로 사용
-
1:1, 1:N, N:M으로 연결 가능
-
-
인터넷 프로토콜의 약자로 인터넷 망을 통해 패킷을 전달하는 프로토콜
-
비연결성과 비신뢰성의 특징을 가짐
-
비연결성 : 패킷을 보내는 길을 정하지 않음
-
비신뢰성 : 패킷의 완전한 전달을 보장하지 않는 것
-
-
도메인 주소를 IP 주소로 변환해주는 시스템
-
URL 입력시 ISP(인터넷 서비스 프로바이더)가 관리하는 DNS해석기에 요청을 라우팅시킴
-
DNS해석기 루트 서버에 top-level의 서버 주소를 요청
-
top-level에서 second-level, second-level에서 sub DNS 서버를 요청하여 최종적으로 IP주소를 얻게 됨
-
서버의 부하를 분산시켜주는 시스템
-
L4 로드밸런서와 L7 로드밸런서가 있음
-
L4 로드밸런서
-
4계층 이하의 정보를 가지고 로드를 분산,
-
특히 MAC주소, IP주소, 포트정보를 가지고 트래픽을 분산
-
-
L7 로드밸런서
-
응용 계층의 정보를 가지고 로드 분산
-
패킷 내용을 확인하고 분산해서 DDOS같은 비정상적인 트래픽도 필터링할 수 있음
-
-
시스템의 자원과 동작을 관리하는 소프트웨어
-
프로세스, 저장장치, 네트워킹, 사용자, 하드웨어 등을 관리
-
코드, 데이터, 힙, 스택으로 이루어져 있음
-
코드는 소스코드가 들어가는 부분
-
데이터는 전역변수, 정적변수가 할당되는 부분
-
힙은 사용자가 직접 관리하는 영역으로 데이터가 동적으로 할당되는 공간
-
스택은 함수의 호출정보, 지역변수, 매개변수 등이 저장됩니다.
-
-
프로세스는 실행중인 프로그램
-
스레드는 프로세스 안에서 실행되는 흐름 단위
-
프로세스는 메모리와 CPU를 프로세스마다 할당받아서 사용
-
스레드는 프로세스 안에서 다른 스레드와 메모리와 CPU를 공유해서 사용
-
준비큐(CPU 할당을 대기중인 프로세스로 구성) 있는 프로세스에 대해서 CPU를 할당하는 방법
-
FCFS, SJF, SRT, Priority Scheduling, Round Robin 방식이 있음
-
비선점 스케줄링(먼저 실행되고 있는 프로세스가 있을 경우 대기하는 방식)
-
FCFS : 먼저 CPU를 요청하는 프로세스를 먼저 처리하는 방식
-
SJF : 평균 대기 시간을 최소화하기 위해 사용하는 방식
-
-
선점 스케줄링(우선순위가 더 높은 프로세스가 올 경우 어떤 프로세스가 자원을 사용하고 있어도 강탈함)
-
SRT : 최단 잔여시간을 우선으로 하는 방식
-
라운드 로빈 : Time Sharing System을 위해 설계된 스케쥴링(공평하게 n초씩 나누기)
-
Priority Scheduling : 우선 순위가 높은 프로세스에 CPU를 우선 할당하는 방식
-
-
모든 프로세스에게 메모리를 할당하기에는 메모리의 크기가 한계가 있어서 사용하는 방법
-
프로세스에서 사용하는 부분만 메모리에 올리고, 나머지는 디스크에 보관하는 기법
-
프로세스가 자원을 얻지 못해, 다음 작업을 못하는 상태
-
예를 들면 P1, P2가 각각 자원 A, B를 얻어야 되는데 P1이 A를 P2가 B를 가지고 있어서 서로 무한정 기다리는 상태
-
상호배제, 점유대기, 비선점, 순환대기가 동시에 발생해야 성립
-
상호 배제 : 자원은 한 번에 한 프로세스만 사용할 수 있어야 한다.
-
점유 대기 : 최소환 하나의 자원을 점유하고 있으면서 다른 프로세스에 할당되어 사용하고 있는 자원을 추가로 점유하기 위해 대기하는 프로세스가 있어야 한다.
-
비선점 : 다른 프로세스에 할당된 자원은 사용이 끝날 때까지 강제로 빼앗을 수 없어야 한다.
-
순환 대기 : 프로세스가 각자 보유한 자원을 서로서로 순환적으로 요구해야되는 상태
-
-
한 스레드가 진행중인 작업을 다른 스레드가 간섭하지 못하게 막는 것
-
동일한 변수에 동시에 접근 방지(두 사람이 동시에 스위치 누르면 2회 누름이 아님 1회 누름)
-
뮤텍스
- 간섭받으면 안되는 변수들을 임계 영역(락을 얻은 단 하나의 스레드만 출입 가능) 설정
-
세마포어
-
다수의 프로세스나 스레드의 여러 개의 공유자원 접근을 제한하는 방법
-
식당 출입할 때 P라고 외치고 나갈떄 V외쳐서 남은 좌석 표시
-
-
데이터나 값을 미리 복사해 놓는 임시장소
-
캐시의 접근 시간에 비해 원래 데이터를 접근하는 시간이 오래 걸리는 경우에 사용
-
값을 다시 계산하는 시간을 절약하고 싶은 경우에 사용
-
파이썬
-
객체지향언어
-
동적 타이핑 언어(변수 선언 불필요, 런타임에서 타입을 결정하여 자바보다 느림)
-
-
자바
-
객체지향언어
-
정적 타이핑 언어
-
JVM 위에서 실행되기 때문에 OS 관계없이 같은 동작
-
-
C
-
절차지향언어
-
각 OS 머신에 맞는 기계어로 컴파일 속도를 요하는 프로그램 등에서 사용
-
- Iterator(반복자)를 생성해주는 Generator 함수를 정의하는 데 사용
-
특정한 데이터가 저장된 주소 값을 보관하는 변수
-
값에 의한 호출이 아닌 참조에 의한 호출 가능
-
자바 오픈소스 애플리케이션 프레임워크 중 하나
-
스프링의 기본철학은 특정 기술에 종속되지 않고 객체를 관리할 수 있는 프레임워크를 제공하는 것
-
컨테이너로 자바 객체를 관리하면서 DI와 IOC를 통해 결합도를 낮추게 됨
-
객체간의 의존관계를 미리 설정해두면 스프링 컨테이너가 의존관계를 자동으로 연결
-
직접 의존하는 객체를 생성하거나 검색해서 가져올 필요가 없어서 결합도가 낮아지는 장점이 있음
-
Field Injection(필드 주입)
-
@Autowired 애너테이션을 속성에 바로 주입
-
생성자 or Setter가 없으므로 수동 의존성 주입이 필요한 테스트 불가능
-
의존성이 프레임워크에 강하게 종속되는 문제점 발생
-
@Controller
public class MemberController {
@Autowired
private MemberService memberService;
}
-
Setter Injection(수정자 주입)
-
setter 메소드를 통해 의존성 주입
-
속성에 final를 작성할 수 없으므로 의존성 불변을 보장할 수 없음
-
런타임 중 setter를 다시 호출하여 이미 주입된 의존성 변경이 가능
-
주로 런타임 중 의존성 수정하거나 선택적 의존성(의존성 주입이 반드시 필수가 아닌 것을 의미)에 사용
-
@Controller
public class MemberController {
private MemberService memberService;
@Autowired
public void setMemberController(MemberService memberService) {
this.memberService = memberService;
}
}
-
Construction Injection(생성자 주입)
-
생성자를 통해 의존성 주입
-
객체의 최초 생성 시점에 스프링이 모든 의존성을 주입
-
생성자 호출 시 final에 의해서 의존성 주입이 최초 1회만 이루어짐
-
생성자 주입은 의존관계 불변이므로 NullPointerException 방지(다른 방식은 직접 객체를 생성하여 방지)
-
@Controller
public class MemberController {
private final MemberService memberService;
@Autowired
public MemberController(MemberService memberService) {
this.memberService = memberService;
}
}
-
제어권이 사용자에게 있지 않고, 프레임워크에 있어서 필요에 따라서 사용자의 코드를 호출하게 됨.
-
스프링에서는 인스턴스의 생성부터 소멸까지 개발자가 아닌 컨테이너에서 대신 관리
-
관계형 데이터베이스를 객체 지향 언어로 변환해주는 기술
-
비즈니스 코드가 DB 테이블에 바로 접근하게 도와줌
-
ORM을 위해서 자바에서 제공하는 API
-
자바 객체와 DB테이블을 매핑
-
구현체로는 하이버네이트가 있음
-
비즈니스 로직에 집중하고 객체 중심의 개발을 할 수 있게 됨
-
메소드를 호출하는 것만으로 쿼리를 수행해서 생산성이 향상되고 유지보수 비용이 줄어듬
-
특정 DB에 의존하지 않게 됨
-
직접 SQL을 호출하는 것보다는 조금 느리고 복잡한 쿼리 같은 것은 메소드로 처리하기 힘듬
-
브라우저의 DNS서버에서 도메인명으로 IP주소를 가져오게 됨
-
HTTP Request 메시지 작성 그 후 OS의 프로토콜 스택에 메시지 전송을 의뢰
-
프로토콜 스택이 LAN에 제어정보를 붙인 패킷을 LAN 어댑터로 넘기게 되고
LAN어댑터는 이것을 전기신호로 변환시켜 LAN케이블로 송출 -
송신한 패킷은 허브, 스위치, 라우터를 경유해서 프로바이더에게 전달
-
패킷은 수많은 엑세스 회선을 통해서 pop를 거쳐서 인터넷 핵심부에 들어가게 되고
많은 고속 라우터들 사이로 패킷이 상대방 서버까지 도달하게 됨 -
서버측의 LAN에 도착하게 되면 방화벽이 패킷을 검사하게 됨
-
이상이 없을 경우 캐시서버가 먼저 응답 데이터가 있는지 확인
-
응답 데이터가 없을 경우 웹서버에 전송
-
패킷이 웹서버에 도착하면 이제 프로토콜 스택은 패킷을 추출해서 WAS에 전달
-
WAS는 응답 메시지를 만들어서 다시 클라이언트로 보내게 되고 보낼떄는 이미 말씀드린 방법대로 전달
-
HTTP의 경우에 상태와 연결에 대한 정보를 저장하지 않아서 이것을 도와주는 것이 쿠키와 세션
-
쿠키
-
사용자 정보가 기록된 텍스트 파일
-
브라우저에 저장되면서 통신할 때 (HTTP) 헤더에 포함되어 전송
-
HTTP 통신중에 쿠키 정보가 노출될 수 있기 때문에 보안에 취약
-
-
세션
-
사용자의 정보를 서버에 저장
-
브라우저가 종료될 때까지 유지
-
서버에 저장되기 때문에 보안에 강함
-
-
REST를 기반으로 서비스 API를 구현한 것
-
REST는 자원의 표현, 즉 이름으로부터 자원의 정보를 주고 받는것
-
자원을 URI로 표현하고 자원에 대한 행위는 HTTP Method로 표현한 것이 REST API
-
RESTful은 REST의 원리를 잘 따르는 시스템
-
자원을 URI로 행위에 맞는 적절한 HTTP method를 사용한 것이 RESTful한 메소드
-
즉 RESTful한 메소드는 누구든 각 요청의 의도를 쉽게 파악할 수 있어야 함
-
RESTful하지 않은 메소드를 예로 들면 CRUD기능을 모두 POST만으로 처리한 것
-
100번대 : 조건부 응답, 요청을 받아서 지금 처리하고 있음을 의미
-
200번대 : Request가 성공적으로 처리되었음을 의미
-
300번대 : Redirection으로 클라이언트를 지정된 위치로 이동하게 하는 것
-
400번대 : 클라이언트 오류로 HTTP 요청이 잘못되거나 권한이 없을때 나타나게 됨
-
500번대 : 서버 오류로 서버가 요청을 제대로 수행하지 못할때 발생
-
HTTP에 3가지 문제가 있어서 이를 보완하기 위해 사용하게 됨
-
평문 통신을 해서 도청이 가능한 점
-
통신상대를 확인하지 않아서 위장이 가능
-
완전성을 증명할 수 없기 때문에 변조가 가능
-
-
HTTP에서 통신하는 소켓을 암호화 프로토콜을 사용하여 TCP와 통신
-
암호화 프로토콜을 사용함으로써 암호화, 증명서, 변조를 방지할 수 있음
-
Get
-
웹 브라우저가 웹 서버에 데이터를 요청할 때 주로 사용
-
전달되는 데이터가 인코딩되어 URL에 포함되어 전송
-
이 데이터가 255개의 문자를 초과하면 문제가 발생 여지 있음
-
-
Post
-
웹 브라우저가 웹 서버에 데이터를 전달하기 위해 주로 사용
-
HTTP Body에 포함되어 전송
-
URL에 표시되지 않으며 많은 양의 데이터를 전달하기 적합
-
-
서버와 클라이언트 간의 중계 서버로서 통신을 대신 수행하는 역할
-
http 메시지를 정리하는 대리인
-
클라이언트의 대리역할, 서버의 대리역할 둘다 가능
-
client - (Forward Proxy) - Internet - (Reverse Proxy) - Server
-
Forward Proxy
-
클라이언트 대신 서버에 요청을 보내주는 역할
-
로컬 네트워크와 인터넷 사이 오가는 트래픽을 제어할 수 있음
-
-
Reverse Proxy
-
서버 대신 클라이언트에 응답을 보내주는 역할
-
웹 서버의 보안 기능을 추가 가능
-
빠른 웹 서버 캐시를 느린 웹서버 캐시 앞에 놓음으로써 성능 개선 가능
-
-
프록시 장점
-
유해사이트 등 필터
-
허가된 클라이언트만 접근 가능하게 하는 접근 제어
-
캐싱(서버까지 거치지 않고 바로 프록시에서 캐싱된 정보 이용하여 응답가능)
-
익명화(신원 정보를 제거하여 보안에 기능)
-
로드 밸런싱
-